
毫末智行数据智能科学家贺翔看来,自动驾驶行业可以被分成三个时代:1.0时代是硬件驱动,主要依靠激光雷达和人工规则的认知方式提供自动驾驶方案;2.0时代是软件驱动,特点是传感器单独输出结果,用小模型和少数据的模式提供自动驾驶方案;3.0时代是数据驱动时代,采用多模态传感器联合输出结果,用大模型大数据的模式提供自动驾驶方案。
2023年2月22日,由盖世汽车主办的2023第二届汽车芯片产业大会中,贺翔表示,与传统CNN相比,Transformer计算需求量提升了约100倍,但只有6%贡献了大部分价值,也就是说90%以上的计算需求量贡献的价值很低,导致大量功耗和过度浪费,因此,如何将这种技术方案物尽其用呢?
贺翔提出两点:云端需要低碳计算,车端需要实现高效部署。

贺翔 | 毫末智行数据智能科学家
以下是演讲内容整理:
2018年以前,在进行AI领域的NLP自然语言处理时,可以用到包括Word2Vec、LSTM在内的很多种方法,但在2018年之后Transformer/ViT统一了全部的应用,CV领域也是如此……进入大模型时代,可快速堆叠扩大参数的Transformer模型逐渐成为AI任务处理的主流方法。
Transformer大模型需要的数据特点
过去几年里,Transformer的参数量从最早的千万规模,很快攀升到了十亿、千亿,现在的大模型都是千亿以上。随着参数量增长,这种模型的能力也会呈线性上升,可以超过人类的平均水平。然而,这种大参数的模型也会带来很多挑战,比如随着参数增加,模型对算力的需求会快速地增长,并远超过摩尔定律下的增长速度。
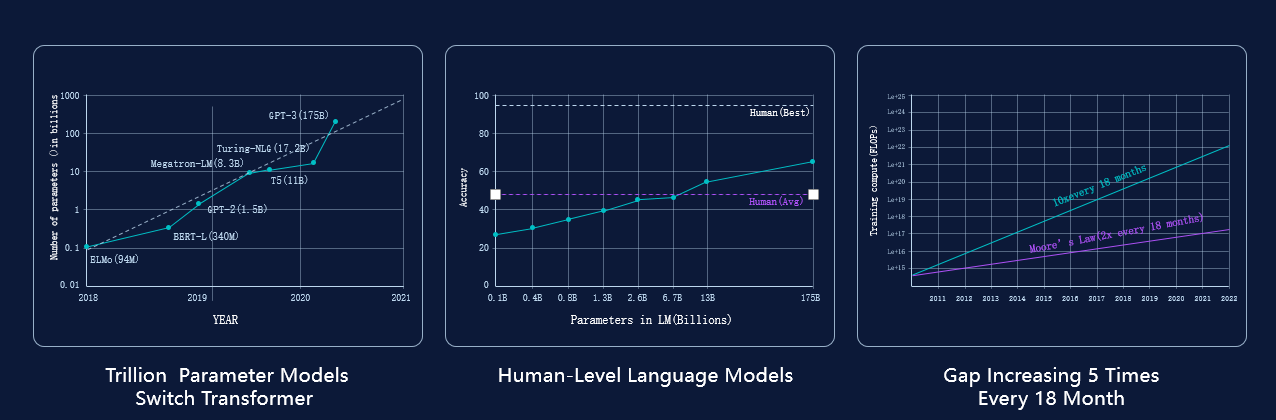
图片来源:嘉宾演讲材料
要训练大参数Transformer模型,对数据有什么要求呢?我主要结合两个案例进行说明,OpenAI ChatGPT和Google PaLM,ChatGPT前身GPT3.0的参数规模大概在1750亿,训练语料包含5000亿tokens;Chat GPT的最大改进点在于引入人类反馈的语料,来进行强化学习,提升模型效果,确实达到了令人惊叹的效果。所以很多人也在说:“ChatGPT一出来,有一种AI奇点临近的感觉。”
第二个是Google PaLM模型,这个模型的参数规模在5400亿,数据规模有7800亿tokens,覆盖100种语言。
结合以上两种模型我们发现,大模型需要的数据有三个特点,第一参数规模和数据规模大;第二内容丰富,语料多样;第三,最好引入大量的人类反馈语料,通过反馈优化模型效果。基于这些观察我们提出一个问题:要想在自动驾驶行业取得大模型能力的突破,对数据会有怎样的要求?依据上文归纳的三个特点,可以得出结论:数据规模大、多样性好、引入用户反馈数据对模型进行优化。
自动驾驶落地需要大规模且多样性的训练数据
但是,自动驾驶行业跟互联网有一个很大的差异,那就是互联网拥有全世界的人每时每刻创造的大量数据,而自动驾驶行业的路测数据相对有限。那么如何收集到大量自动驾驶数据?只能将数据采集系统设置在量产车上,让每一个车主都成为数据来源,这样才能采集到足量的数据。
以下是两种统计图,左图是毫末量产车覆盖全国各类道路的真实人驾数据,目前毫末的量产车已经覆盖到全国大部分县市,右图是毫末数据覆盖的具体场景,包含各种各样的路况,大概有几千万公里通过量产车回传的数据。
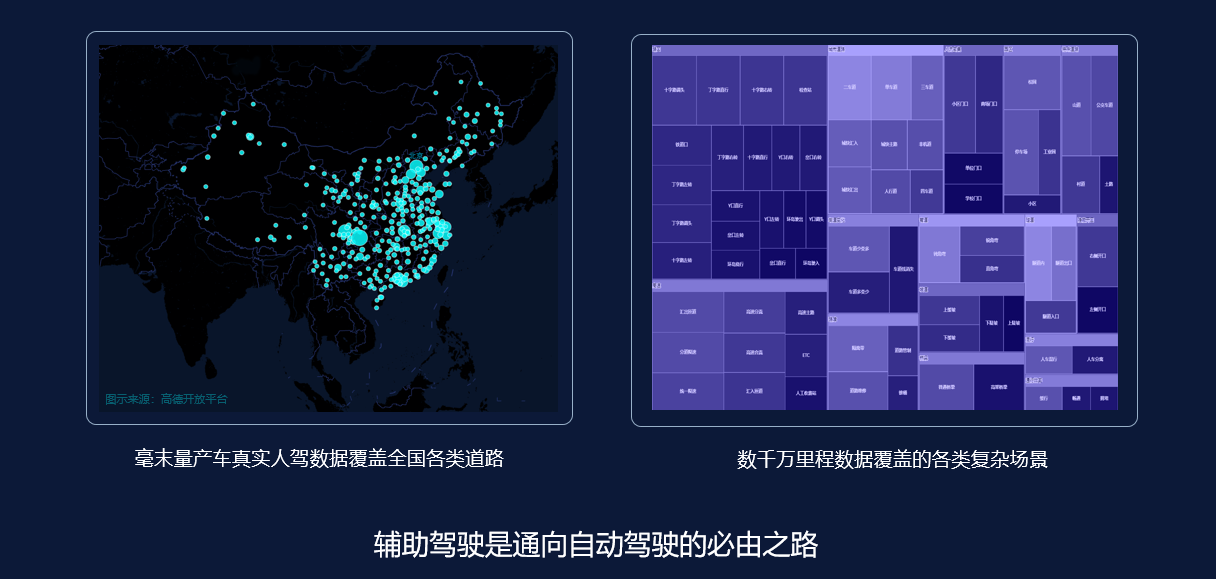
图片来源:嘉宾演讲材料
为了实现自动驾驶的技术突破,辅助驾驶到自动驾驶的渐进式道路是必由之路。根据行业的发展以及我们对十几年里自动驾驶行业的认知,自动驾驶行业可以被分成三个时代:1.0时代是硬件驱动,主要依靠激光雷达和人工规则的认知方式来做自动驾驶。2.0时代是软件驱动,特点是传感器单独输出结果,用小模型和少数据的模式做自动驾驶。3.0时代是数据驱动时代,采用多模态传感器联合输出结果,使用可解释的场景化驾驶常识的认知方式,大模型大数据的模式做自动驾驶。
毫末智行成立三年时间,一直致力于自动驾驶量产车的研发,从辅助驾驶开始做起,基于量产车大规模回传数据,建立了中国首个自动驾驶数据智能体系MANA,并且为了训练大模型数据,建立了中国首个智算中心。
毫末智行的自动驾驶软件经过多年的升级,已从1.0版本发展到3.0版本,覆盖了长城汽车旗下20多个车型。我们的另一项业务是末端物流自动配送车,这是L4级别的全无人自动驾驶,适用于最后一公里配送。目前已与美团、京东、达达等头部客户建立合作,并在北京顺义进行常态化运营。这种配送车价格低廉,只需12.88万元即可购买,是一种低成本的L4解决方案。
毫末智行拥有实时的数据看板,显示辅助驾驶里程接近3700万公里,小车配送订单超过15万单,这些数据来源于量产车的大规模回传,其数据规模和多样性也在快速增长。
基于大规模量产数据的优势,毫末智行也建立了智能学习体系MANA。该体系包含五个大模型,用以学习自动驾驶的策略:其中有人驾自监督认知大模型、视觉自监督大模型、多模态互监督大模型、3D重建大模型和动态环境大模型(重感知城市NOA系统落地的关键)。

图片来源:嘉宾演讲材料
然而,大数据、大参数、大模型也带来了巨大的挑战。与传统CNN相比,Transformer计算需求量提升了约100倍,但其中6%贡献了大部分价值,也就是说90%以上的计算需求量贡献的价值很低,导致大量功耗和过度浪费,因此,如何将这种技术方案物尽其用呢?主要分两个方面:云端需要低碳计算,车端需要实现高效部署。
云端如何实现低碳计算?
此前,毫末智行与火山引擎联合推出了自动驾驶行业首个智算中心,其浮点运算性能达到67亿亿次/秒,存储带宽为2T/秒,网络带宽为800G/秒,这样的硬件配置旨在快速训练大规模的数据。智算中心不仅在硬件上配置豪华,还在系统上进行了深度优化:在计算方面,引入了Lego高性能算子库,包含500多个高性能算子,能够快速适配200多种网络结构;在通信方面,引入了ByteCCL通信优化,并建立了完整的大模型训练框架。
接下来是毫末智行的具体做法,Transformer模型在训练过程中会产生大量无效、低价值的数据,这个时候我们引入了Sparse MoE稀疏激活,大幅降低无效计算;通过跨GPU多机共享Expert,支持万亿参数大模型训练;支持多任务并行,同时处理图片、点云、文本等多种模态的信息,既保证模型稀疏性,又保证计算效率
以上举措并行,我们最终希望将大数据训练成本降低100倍以上。
车端如何高效部署?
这种大模型、大参数在车端如何实现?这是一个关乎自动驾驶性能和安全的重要问题。目前,车端的摄像头分辨率普遍在200万像素,能看清150-200米以内的物体,而毫末智行、长城汽车和高通合作推出的800万象素摄像头可以提高视野清晰度。
不能忽视的一点是,目前手机摄像头的分辨率都达到了5000万甚至1个亿象素,车端摄像头是否也会朝这个方向发展?如果车端摄像头分辨率提升至手机摄像头的水平,数量增加到10-12个,所收集到的数据规模就会非常庞大,如何在有限的芯片资源上处理这些数据,算力是首先要跨过的门槛。
我们认为这个问题需要从模型和芯片两个方面来解决。首先,在模型方面,我们不能简单地把云端的大模型直接移植到车端,而需要进行模型轻量化处理。例如,我们尝试了CNN和Transformer结合的模型,并取得了显著的效果。
其次,在芯片方面,已经有一些学者在研究Transformer专用的芯片,这种芯片利用了Transformer内部计算的特点,只保留有价值的计算,并将低价值的部分用静态方式实现,从而提高效率和降低功耗,这对于我们在车端芯片上快速部署大模型有很大帮助。
结合具体需求,我们对市面上的各类芯片进行了对比,其中高通芯片在75W功耗的情况下每秒可以处理两万帧图片,和我们的需求接近,除此之外,该芯片在车规级安全方面也表现出色。目前,毫末智行基于高通芯片建设的系统已经在各个城市路测,端到端延迟仅为30ms。下图是我们采集数据的基本框架,系统将不同传感器的数据进行处理,汇集到统一BEV空间内并进行融合,得到感知结果并输出,相比原来效果有显著提升。

图片来源:嘉宾演讲材料
最终,我们向客户交付的是结合了控制、决策等算法,整合了软硬件的一体化解决方案——小魔盒3.0(HPilot3.0),目前已经装配置量产车上,它具有以下特点:算力高(单片可提供360T)、缓存大、推理速度快、延迟低,部署方便等。基于小魔盒3.0(HPilot3.0)配置的传感器系统也具备诸多优势,可以实现全场景冗余感知;保障驾驶安全性和体验。
总而言之,毫末智行所推出城市NOH项目的领先性主要有三:一是采用了重感知技术路线;二是运用了大模型技术。为了解决重感知在车端落地问题,我们规划了五种不同功能和特点的大模型;三是建立了用户闭环系统。为了优化大模型,我们需要海量、多样、可反馈的数据,毫末智行可以用部署在量产车上的辅助驾驶系统收集全国各地的驾驶数据并用以训练大模型,再将优化的结果应用在辅助驾驶系统上,从而形成闭环。
根据以上三点,这是我们的推进计划:预计2024年H1落地100个城市,下半年进一步拓展落地区域,最终实现完全无人驾驶。“让机器智能移动 给生活更多美好”——这是毫末智行始终不变的愿景。
(以上内容来自毫末智行数据智能科学家贺翔于2023年2月22日由盖世汽车主办的2023第二届汽车芯片产业大会上发表的《自动驾驶3.0时代》主题演讲。)
本文地址:https://auto.gasgoo.com/news/202302/28I70332235C111.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921



















