

“为了支撑智能驾驶业务,我们不仅需要模型,需要不同形式的算力,也需要在终端部署的边缘场景上做边缘方面的协同。”华为昇腾计算业务CTO周斌表示,“为此,华为深耕行业数年,2018年就发布了第一代全栈全场景AI解决方案。此后,我们克服了重重困难,并持续引进资源和人才,在底层计算架构、核心硬件、大规模集训系统、操作系统、编译器、编程语言等方面进行了全面投入,这些系统有力支撑了我们在大规模智能驾驶领域的拓展。”
2023年3月23-24日,在2023光谷人工智能产业生态大会——智能网联汽车专场。周斌表示,目前,华为实现了车端、路端、云端多领域业务的全方位覆盖。“小到车载零部件,大到系统性的AI计算中心,都可以用华为昇腾AI计算架构来支撑。”

周斌 | 华为昇腾计算业务CTO
以下为演讲内容整理:
人工智能是新一代汽车的重要方向,伴随着汽车智能化时代的到来,数据驱动智能体系以及AI算力会成为智能网联车非常重要的生产力要素。
智能网联车行业需求和趋势
随着汽车智能化程度的持续提升,对大规模算力和数据的消耗也会不断增加。以国际知名厂商的AI算力需求为例,每年大概需要7-8万次的模型迭代,这意味着其智能计算系统每6-7分钟就要完成一次完整的业务循环,并且业务循环数据量巨大。据我们评估,像ChatGPT这种规模的模型,需要消耗的算力约在10000P以上。
从L2-L4,有人说L4单车车载需要上千T,同时业务更新迭代越来越快,由原来的一周左右加速到一两天。如何满足巨大的算力底座需求?华为昇腾计算做了非常重要的工作。
我们探索了自动驾驶业务,自动驾驶对基础设施的要求非常高,因为其复杂的业务流程。首先数据增长量非常大,每辆自动驾驶汽车每天产生的数据量在1TB左右;同时这些数据必须要经过标注、清洗和预处理才成为后续处理的原材料,过程中有巨大的标注处理算力需求。这意味着必须有足够大的模型来支撑这样的业务,尤其是关键业务。训练完成后会消耗巨大的算力和数据,此外业务场景中还要进行各种方针和评估,需要不同形式的算力。最后在实际的车端部署,我们也会在边缘的场景进行协同。
整体来看,基础设施主要呈现出以下几个特征:首先需要高算力能效;其次随着模型规模、数据规模的剧增,以及业务流程的增加,需要高带宽、低延迟的互联网络,这会极大影响整个业务系统的处理能力。
昇腾自动驾驶产品和解决方案
华为在人工智能领域深耕基础,厚植根技术。从2018年第一代全栈全场景的AI解决方案发布,至今已有五年时间。过程中我们克服重重困难,持续跟进市场投入,包括底层计算架构、核心硬件、大规模的集训系统、操作系统、编译器、编程语言以及各种各样的加速库等。
通过全栈自主开放兼容、灵活部署的AI算力底座,我们提供了完整的自动驾驶和智能网联体系的基础解决方案。
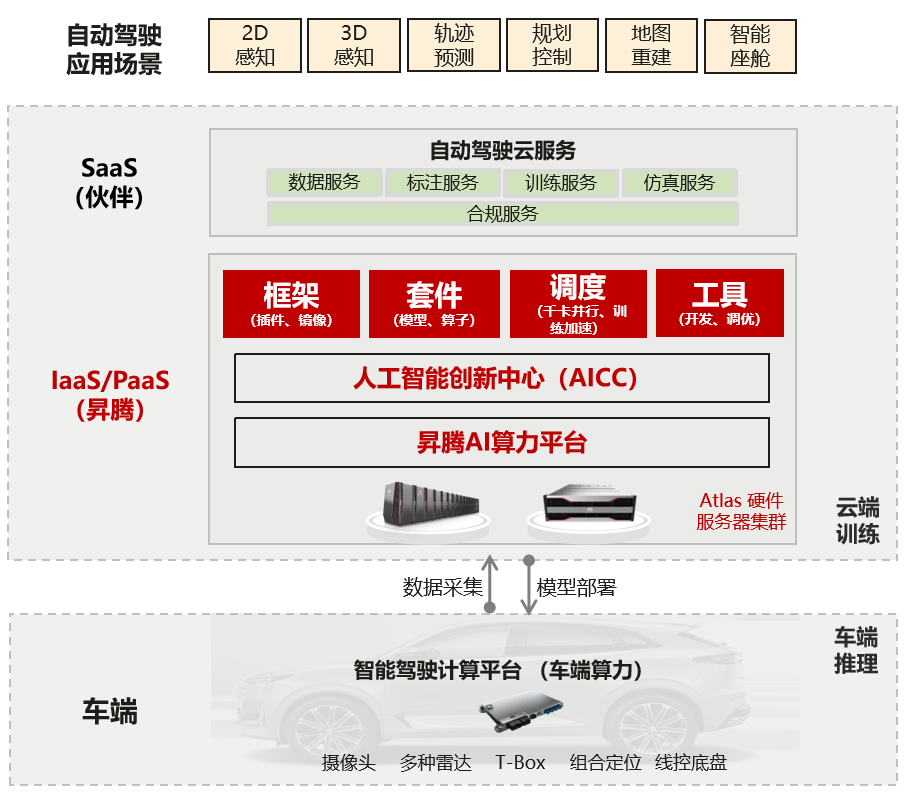
图源:华为昇腾
首先无论是车端还是训练平台,我们都有完整的硬件产品。这些硬件产品经历长时间大规模的产业印证,尤其在算力解决层面,给行业提供了基础的软硬件和围绕着智能网联汽车解决方案的可使用套件。包括框架、训练的模型以及更多的工具和调度系统。
同时,我们联合伙伴一起推出自动驾驶和智能网联云服务体系,更好地支撑上层各种各样的场景需要。我们也拥抱AI开放生态,第一时间以插件化方式灵活的进入开源社区,让大家能够复用已有的模型资产。
除了硬件,围绕着开源生态和模型体系我们打造了整套的软硬件解决方案。大家不用重复造轮子,我们已经做了非常多的适配,并开放给大家使用。首先我们会提供开源的优选模型库。目前提供了超400个开箱即用的人工智能模型,可以进行分布式的大规模训练,使性能得以极大提升;同时构建了诸多行业应用套件,相关的API接口也可以兼容主流的框架,使得我们自主的AI生态能够与社区对接起来。同时,我们与智能网联体系中非常流行的开源套件社区进行了深度的整合,如果您用到这种能力,在华为昇腾体系上可以进行无缝迁移。
我们还做了非常多的模型测试,这个列表还在持续增加。类似ChatGPT这种大规模预系列模型,除了数据、模型算法外,底层算力系统的挑战也非常大;自动驾驶的系统数据量也在急速增加。如何高效的在AI计算机框架下进行调度,是非常大的挑战。
在这个领域,华为和合作伙伴有非常扎实的基础和经验,现在提供了分布式缓存加速,可以进行PB级别的数据预处理,我们集群上信息度大于0.8,可以非常好的调度复杂、大规模的人工智能计算任务,这个平台也是开放的。
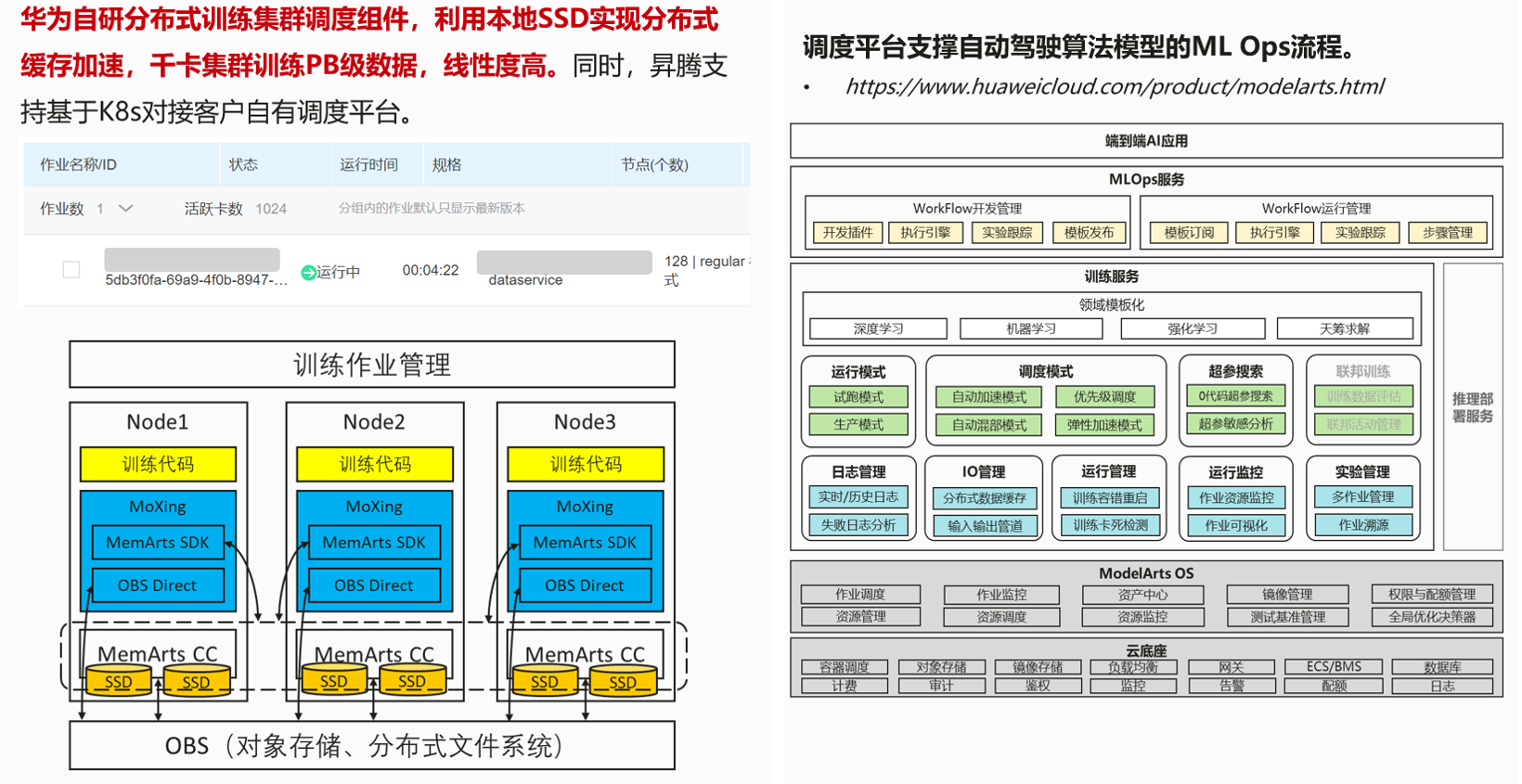
图源:华为昇腾
除调度外,我们的工具链涵盖了自动驾驶、模型、算子、场景开发的全流程,从模型迁移到整个训练,到数据预处理、后处理,再到模型的压缩、减支、优化部署等。在设计体系中,大家可以非常流畅的开发端到端的业务。
我们在武汉部署的极致性能,极简易用的PoD集群,有非常强的算力系统、端到端的软件以及软硬件系统的联合优化。像自动驾驶模型,在1024塔集成训练的条件下,训练效率比友商提升了136%。
合作与展望
通过上述介绍,我们希望通过华为昇腾人工智能计算中心,真正的在智能网联体系中为我们的客户降本增效,实现产业共赢;同事能够为自动驾驶社区提供端到端的业务服务,让智能网联产业得到蓬勃发展。
我们将立足武汉,服务武汉,联合政府、企业、高校共同打造武汉区域的人工智能产业新高地。同时围绕客户第一,为我们的客户提供原厂的专家服务,加速自动驾驶创新应用的开发和落地。
(以上内容来自华为昇腾计算业务CTO周斌于2023年3月23-24日在2023光谷人工智能产业生态大会——智能网联汽车专场发表的《昇腾AI构建智能网联车的算力底座》主题演讲。)
本文地址:https://auto.gasgoo.com/news/202304/3I70336233C601.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921



















