

随着智能交通领域的快速发展,端到端技术已成为辅助驾驶进阶的核心方向。本篇推文系统梳理了辅助驾驶的发展历程,从 1.0 时代的 2D 感知,到 2.0 时代的 BEV 感知,再到如今 3.0 时代的端到端技术,清晰呈现了不同阶段的技术特征与演进逻辑。本篇推文深入解析了支撑端到端辅助驾驶的大模型基础,包括大语言模型、视频生成模型及仿真渲染技术的核心原理与应用场景,并进一步阐述了端到端辅助驾驶的网络架构、技术支撑及训练范式,为理解这一前沿技术提供了全面且深入的视角。
一、辅助驾驶发展历程(一)端到端的定义与演进逻辑
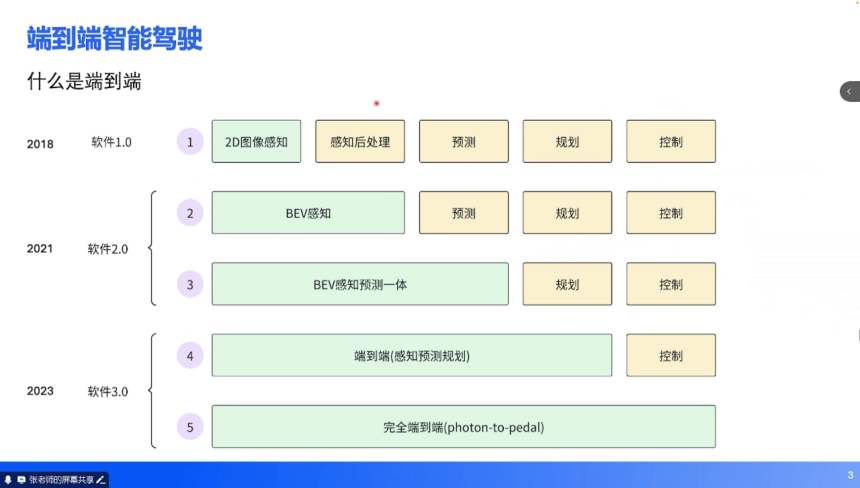
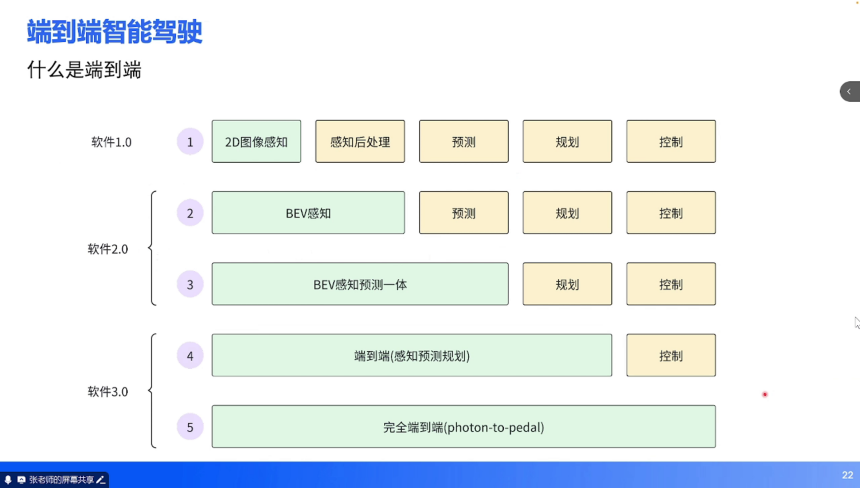
辅助驾驶的发展历程可视为技术范式不断迭代的过程,而端到端技术是这一演进的最新阶段。从行业实践来看,辅助驾驶的发展可划分为五个阶段,对应软件 1.0 到软件 3.0 的技术跃迁:
1. 软件 1.0 阶段(2018 年左右):核心特征是 2D 图像感知与传统算法结合。神经网络仅负责 2D 图像的检测(如车辆 2D 包围框、车道线)与分割(如可行驶区域),后续的感知后处理、预测、规划、控制均依赖 C++ 等传统逻辑代码实现。
2. 软件 2.0 阶段(2021 年左右):BEV(Bird's Eye View,鸟瞰图)感知技术崛起。神经网络实现了 2D 到 3D 空间的转换,将多相机的环视信息融合到 BEV 空间,但预测、规划、控制仍依赖传统算法。该阶段后期出现 “BEV 感知 + 预测一体” 的技术过渡,进一步提升了环境理解的连贯性。
3. 软件 3.0 阶段(2023 年至今):端到端技术成为主流。输入为图像,通过神经网络直接输出期望行驶轨迹(涵盖感知、预测、规划),仅控制环节保留传统算法(将轨迹转化为油门、方向盘等执行指令)。

4. 未来趋势:完全端到端(Photon-to-Pedal),即从传感器光子输入到踏板控制输出的全链路神经网络化,目前仍处于探索阶段。
(二)1.0 时代:2D 感知的技术特征与瓶颈
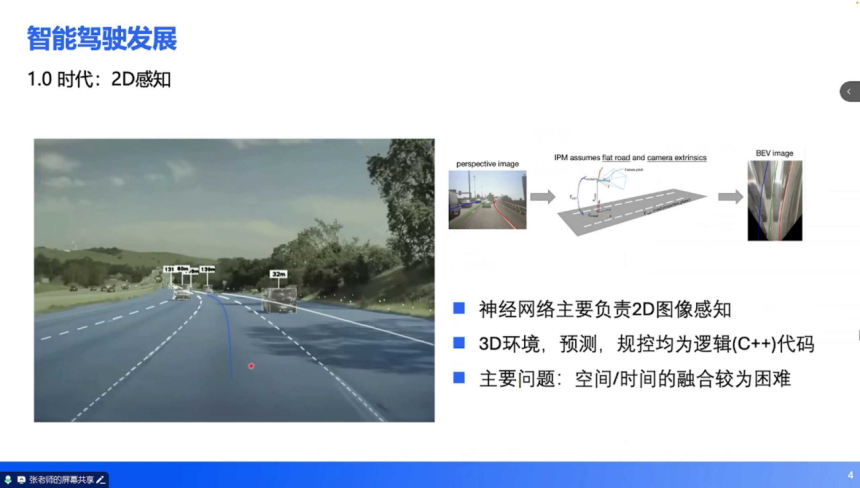
2018-2019 年,深度学习在 2D 视觉任务中趋于成熟,推动辅助驾驶进入 1.0 时代。该阶段的核心技术是 2D 图像感知,具体表现为:
技术实现:神经网络接收 2D 图像输入,输出 2D 检测框(车辆、行人)、车道线、可行驶区域分割等信息。为实现 3D 空间行驶,需通过传统算法(C++)进行后处理:基于逆透视变换(IPM)假设平坦路面和相机外参,将 2D 信息投影到 3D 空间,再进行预测与规控。
核心瓶颈:空间融合困难:环视多相机(通常 6-7 个)的 2D 信息需手动校准融合,不同视角的误差累积导致 3D 定位精度不足。时间融合缺失:单帧图像无法提供动态信息(如目标速度、加速度),需依赖传统跟踪算法补全时序特征,鲁棒性较差。数据闭环缺失:感知与规控的割裂导致难以通过数据驱动优化整体性能,需工程师手动修复逻辑漏洞,迭代效率低下。
(三)2.0 时代:BEV 感知的突破与局限
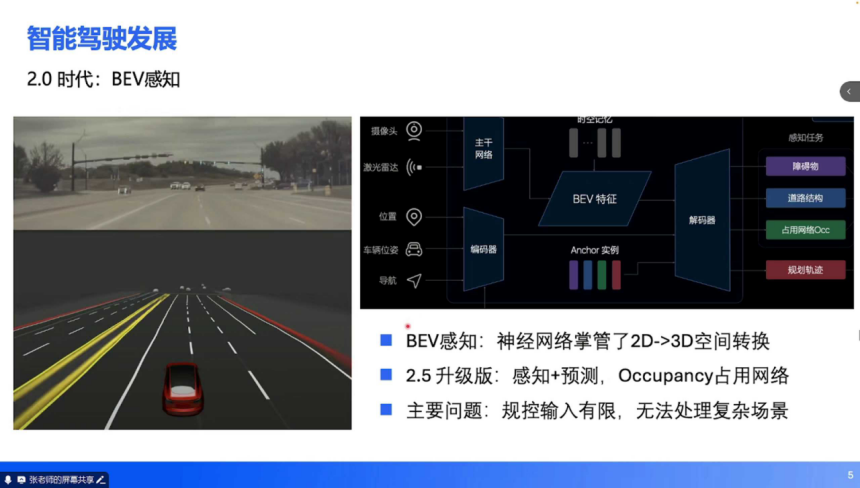
2021 年,Transformer 架构的兴起推动辅助驾驶进入 2.0 时代,BEV 感知成为技术核心:
技术革新:Transformer 具备强大的空间转换能力,可直接将多相机的 2D 图像输入转化为 BEV 空间的 3D 特征,实现 “2D→3D” 转换的端到端化。后续升级版本(2.5 时代)进一步整合预测任务,引入 Occupancy 占用网络(通过体素化表达环境中所有物体的空间占用状态),提升了复杂场景的理解能力。能力边界:该阶段已能支持高速 NOA(导航辅助驾驶)和部分城区场景功能,实现 “可用但需接管” 的落地效果。
核心局限:规控输入受限:神经网络输出的是结构化信息(3D 包围框、车道线矢量等),无法表达复杂语义(如交通牌文字、交警手势、异形路口拓扑),导致对施工区域、多车道红绿灯等场景的处理能力不足。安全冗余依赖:仍需保留 1.0 时代的传统 AEB(自动紧急制动)算法作为安全备份,两套系统的协同逻辑增加了工程复杂度。
(四)3.0 时代:端到端技术的能力跃升与挑战
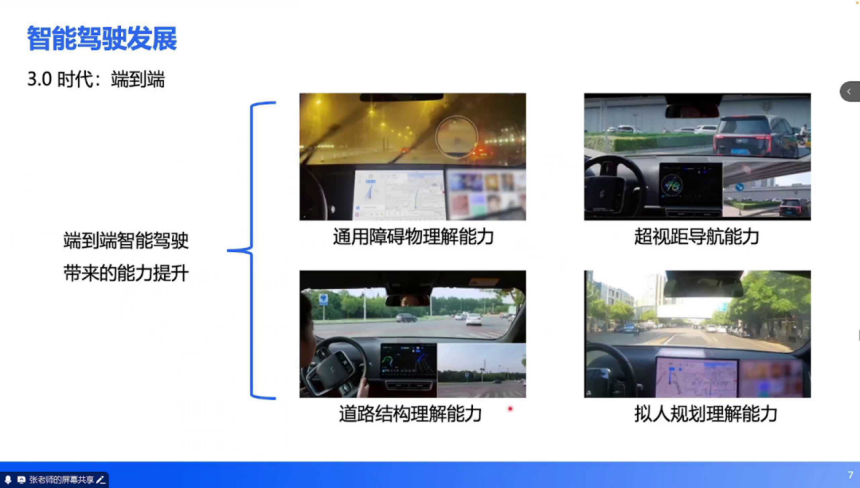
2023 年起,大模型技术(如 LLM、VLM)与辅助驾驶深度融合,推动端到端技术成熟,其核心能力体现在:
通用障碍物理解:可区分异形障碍物(如轮胎、塑料袋)的物理属性,而非仅输出占用网格。例如,面对路中轮胎时会主动绕行,而对塑料袋可能直接通过,决策更贴合实际场景。超视距导航融合:结合高精度地图与导航信息,补全传感器盲区的道路结构(如隧道出口、环岛内部车道),实现 “脑补” 式环境重构。复杂道路结构解析:可理解环岛、多车道对应多红绿灯等复杂拓扑,例如北京西直门桥、上海延安路高架等场景的车道级路径规划。拟人化轨迹规划:通过轨迹点的时间、速度约束间接控制加减速,实现平顺绕行、跟车等类人驾驶行为。
技术挑战:性能波动:端到端模型放大了辅助驾驶的 “上限与下限”。例如,特斯拉 FSD V13 可动态理解施工人员手势并安全通行,但也会出现闯红灯等低级错误(依赖单一模型导致的 “幻觉” 问题)。安全冗余矛盾:1.0/2.0 时代的传统算法需作为安全备份,但当多系统决策冲突时(如 “模型认为无障碍物,传统算法认为有障碍物”),如何取舍成为工程难题。
二、大模型基础:端到端技术的底层支撑
端到端辅助驾驶的成熟依赖三类大模型技术:大语言模型(LLM)、视频生成模型(Diffusion)、仿真渲染技术(NeRF/3DGS)。三者共同构建了 “感知 - 决策 - 验证” 的全链路能力。
(一)大语言模型(LLM):训练范式的启发
大语言模型的训练逻辑为端到端辅助驾驶提供了核心方法论,以 DeepSeek-R1 为例,其训练范式分为四个阶段:预训练(Pretrain):数据准备:收集互联网高质量文本(维基百科、书籍、新闻等),进行 token 化处理(将文字转化为介于单词与字母之间的子序列,每个 token 对应唯一 ID)。目标任务:Next-Token Prediction(预测下一个 token),通过学习 token 间的统计关系理解文本语义。例如,模型能准确预测侦探小说的凶手时,即具备对前文的理解能力。
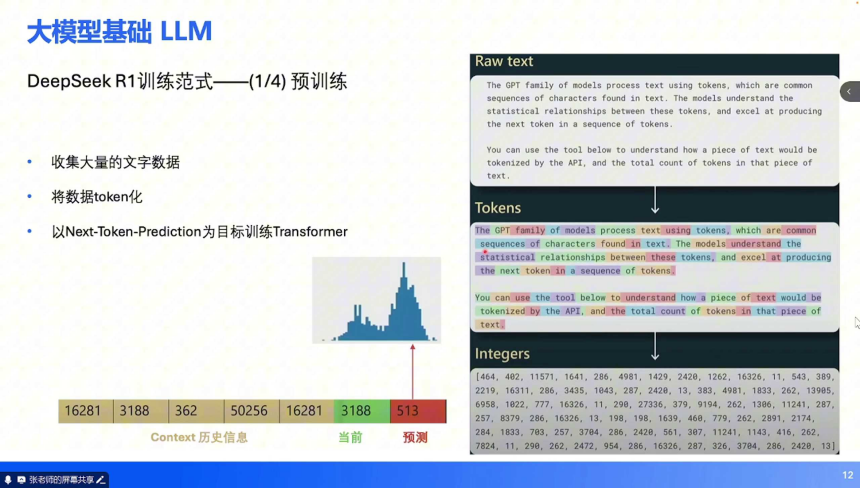
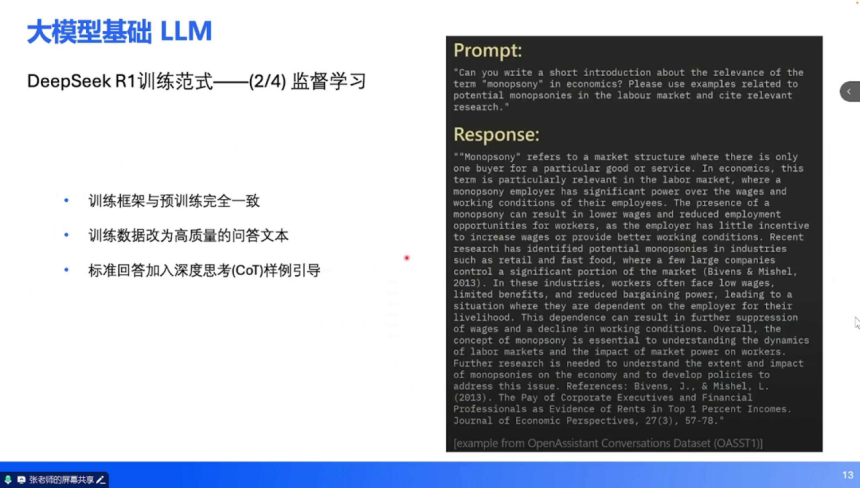
监督微调(SFT):数据升级:使用人工编写的高质量问答数据(如 “如何定义垄断市场”)替代原始文本,训练模型从 “续写” 转向 “问答”。技术细节:引入 Chain-of-Thought(CoT,思维链)样例,引导模型通过分步推理提升回答逻辑性。
强化学习(RL):数据特点:采用可验证任务(数学题、编程题等),通过反馈调整模型参数。例如,模型输出错误解题步骤时,通过奖励函数惩罚并修正。优势:以更少数据消耗更多算力,突破预训练阶段的 “数据瓶颈”,进一步提升模型能力。

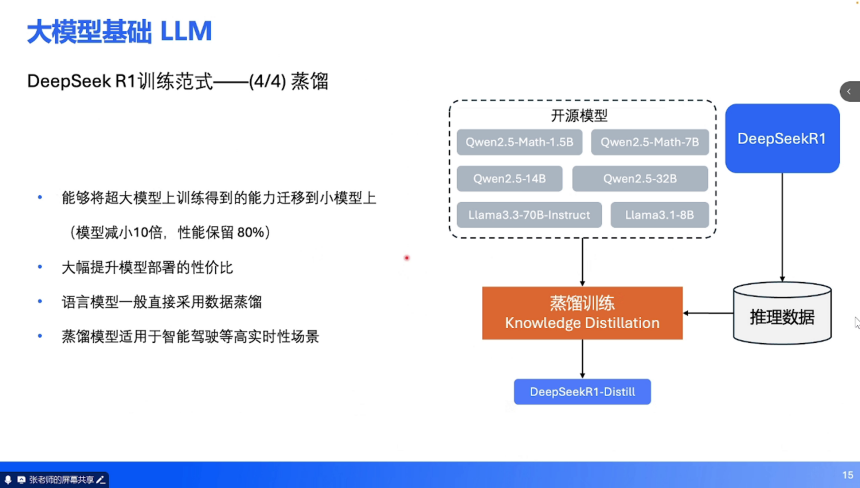
蒸馏(Distillation):目标:将大模型能力迁移到小模型(如参数减少 10 倍,性能保留 80%),通过大模型生成的推理数据训练小模型,降低部署成本。辅助驾驶适配:车端推理需高实时性,蒸馏技术可将云端大模型压缩为车规级小模型,平衡性能与效率。趋势:算力分配从预训练向强化学习倾斜(传统 99% 算力用于预训练,现逐步转向强化学习),通过精细化调优提升模型可靠性。
(二)视频生成模型:动态场景理解的基础
视频生成模型(如 Diffusion)通过 Next-Frame Prediction(预测下一帧图像)实现对物理世界的动态理解,其技术特点包括:
数据与任务:输入为连续视频帧(如 10 秒视频的前 9 秒),输出预测的第 10 秒帧。模型需学习光照、运动、物理交互等时空规律,例如预测车辆转弯时的车身姿态变化。
可控生成:结合文字指令可控制场景参数,如通过 “晴天”“雨夜” 等文本调整光照、天气,生成符合约束的驾驶视频(非真实拍摄,纯模型合成)。辅助驾驶应用:为仿真系统提供动态场景生成能力,例如 DriveDreamer 可通过文字控制光照、车道线拓扑,生成多样化测试场景。

(三)仿真渲染技术:虚拟验证的核心
仿真技术是端到端模型训练与验证的关键,分为开环与闭环两类:
开环仿真:本质:模仿学习(监督学习),模型输入传感器信号,输出人类驾驶员的历史轨迹,不与环境交互。优势:网络结构简单(如 CNN、Transformer),训练成本低,适用于初期能力构建(如特斯拉早期 FSD、小鹏 XNGP 1.0)。局限:依赖高质量数据(劣质样本会导致模型 “学坏”),且模型动作不影响环境(如 “虚拟撞车后场景不变”),无法模拟真实交互。

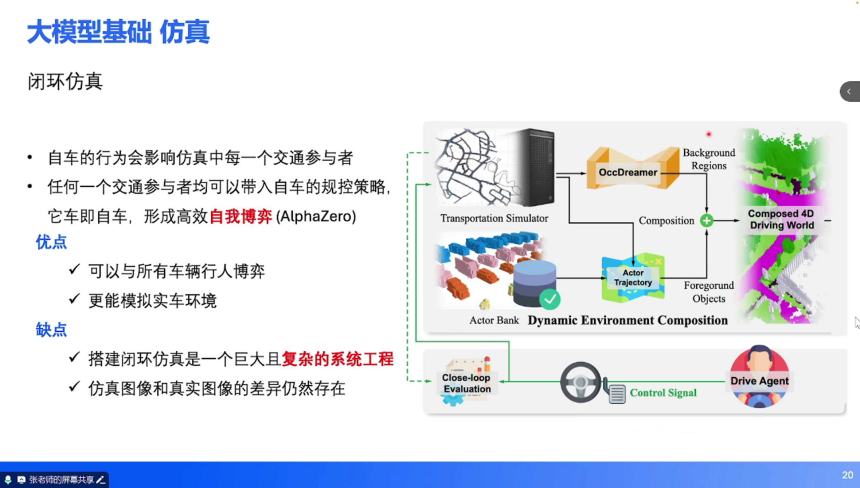
闭环仿真:核心特征:自车行为影响所有交通参与者(如 “自车变道会导致旁车减速”),支持多智能体博弈(每个参与者均可加载自车规控策略,实现 “他车即自车” 的自我博弈)。技术支撑:基于 NeRF(神经辐射场)、3DGS(3D 高斯溅射)构建真实感渲染引擎,生成与物理世界一致的光照、材质效果。优势:可模拟复杂交通博弈(如无保护左转时与对向车辆的交互),更接近实车环境,支持强化学习试错。挑战:系统搭建复杂(需整合物理引擎、渲染引擎、多智能体决策),虚拟与真实图像的 “域差距” 仍未完全消除。
三、端到端辅助驾驶:技术架构与训练范式
端到端辅助驾驶的落地需解决三个核心问题:车端推理的网络架构、技术支撑体系、全链路训练范式。
(一)车端推理:网络架构的实现方式
车端推理需平衡实时性与决策精度,主流架构分为三类:
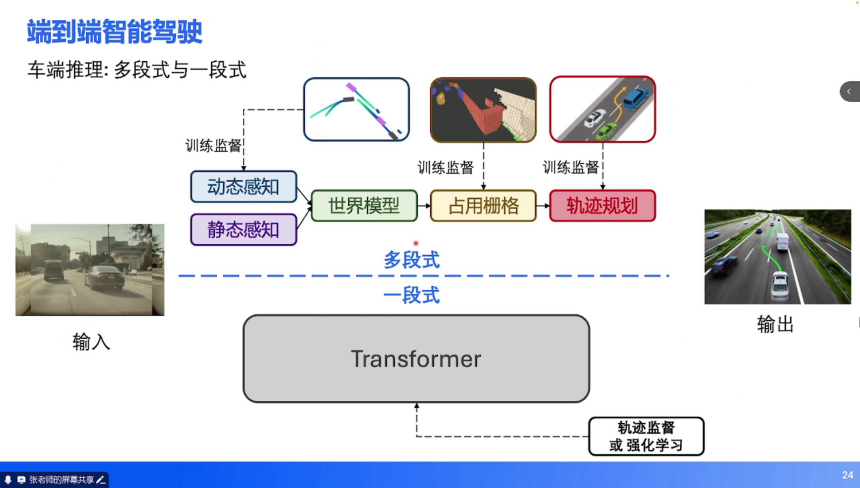
多段式架构:技术路径:继承 BEV 2.0 时代的模块化思路,将端到端任务拆解为 “动态感知→静态感知→世界模型→轨迹规划”,每阶段输出均受监督(如 3D 检测框、车道线、占用栅格)。代表案例:小鹏 UniAD 早期版本,通过多任务监督(人类轨迹 + 中间特征)提升训练稳定性,适用于数据积累不足的场景。
一段式架构:技术路径:单一神经网络(如大参数量 Transformer)直接接收图像输入,输出轨迹(仅受轨迹监督或强化学习奖励),无中间特征输出。优势:避免多模块误差累积,理论上限更高,适用于复杂场景(如城市拥堵路段)。挑战:训练难度大(需海量数据),易出现 “幻觉”(如无中生有障碍物)。
快慢系统:设计理念:借鉴人类 “快思考(直觉)+ 慢思考(推理)” 的认知模式,结合多段式与一段式优势。快系统:多段式架构,输出高频轨迹(帧率 > 10FPS),负责常规场景(如直线行驶、简单跟车)。
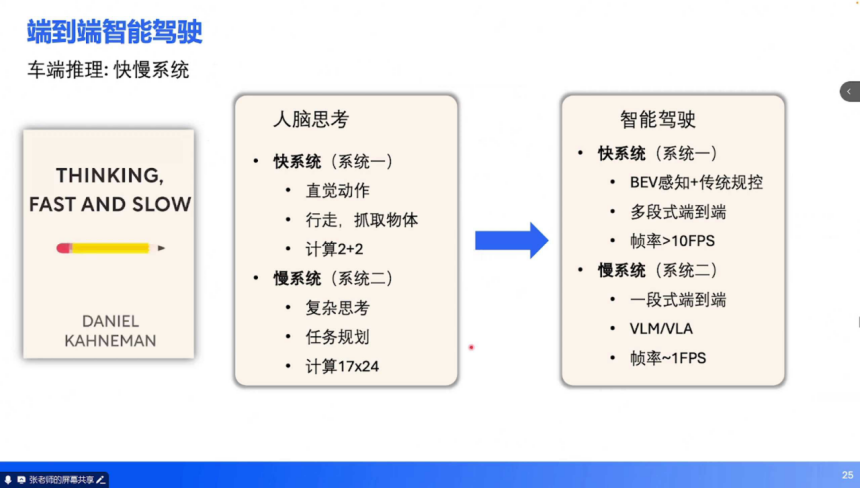
慢系统:一段式架构(如 VLM),输出低频粗指令(帧率≈1FPS),处理复杂场景(如施工区域、交警手势)。案例:DriveVLM 系统中,慢系统通过自然语言描述场景(“天气多云,右侧车道有警车停靠”)并生成元动作(“减速并向右避让”),快系统基于元动作生成精细化轨迹。
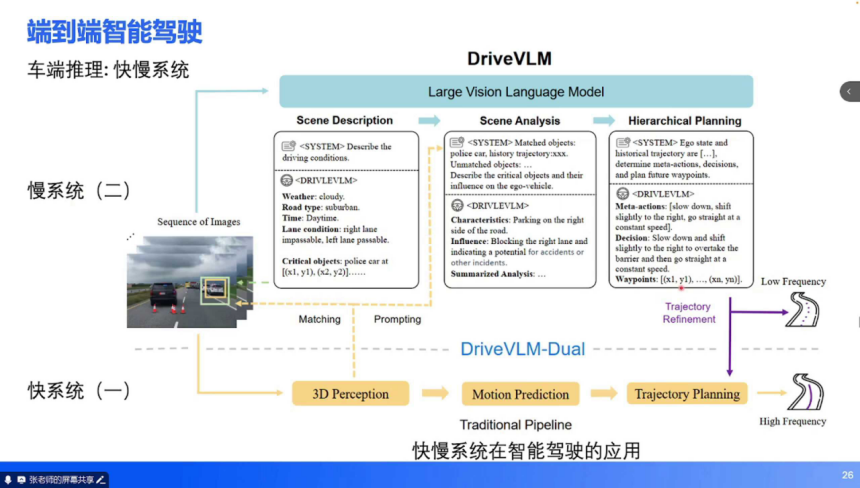
(二)技术支撑:多模态模型与强化学习
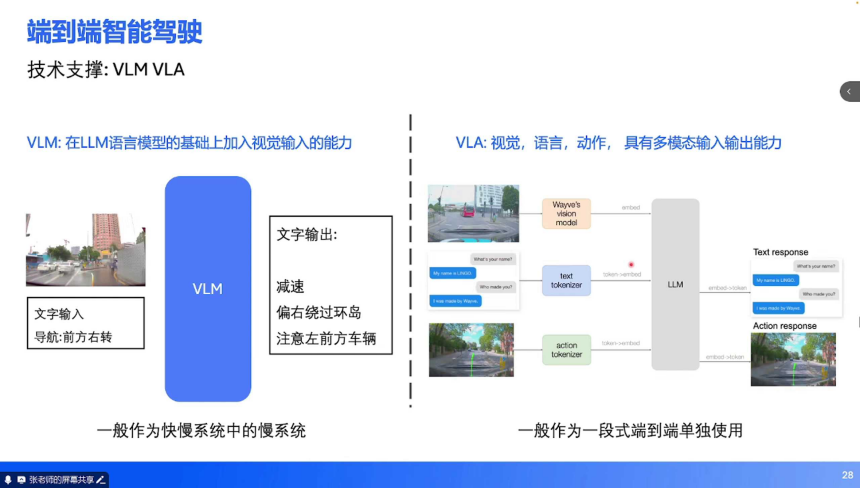
VLM 与 VLA:多模态理解的核心:
VLM(视觉语言模型):在 LLM 基础上增加图像输入能力,可输出文字指令(如 “前方红灯,需停车”),通常作为快慢系统中的慢系统。VLA(视觉 - 语言 - 动作模型):扩展 VLM 的输出能力,支持直接输出动作(轨迹点),输入包含历史动作序列,适用于一段式端到端架构。
强化学习:闭环场景的优化利器:开环 vs 闭环:开环仿真中,模型模仿人类轨迹但无法影响环境;闭环仿真中,模型动作会改变交通参与者行为,支持 “自车与他车的博弈训练”(如 AlphaZero 的自我对弈)。应用价值:通过虚拟试错(如 “闯红灯导致碰撞”)修正模型决策,提升极端场景的安全性。例如,模型在仿真中多次尝试无保护左转后,可学会根据对向车速动态调整起步时机。
(三)训练范式:全链路的迭代逻辑
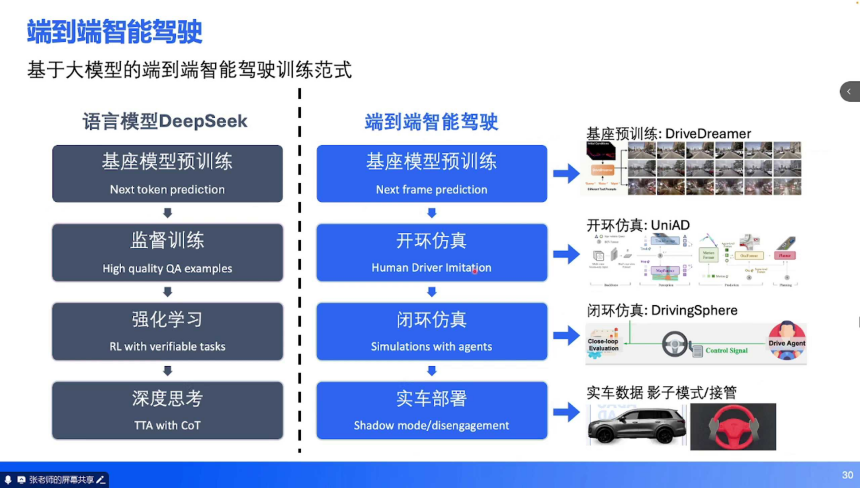
端到端辅助驾驶的训练流程与大语言模型一脉相承,分为四个阶段:
基座预训练:基于视频生成模型(如 DriveDreamer)进行 Next-Frame Prediction,学习驾驶场景的物理规律(如车辆运动惯性、光照变化),构建世界模型基础。开环仿真(模仿学习):在真实采集的驾驶数据中训练,让模型模仿人类轨迹(如人类在环岛的转向时机、跟车距离),快速积累基础驾驶能力。
闭环仿真(强化学习):在虚拟环境中通过自我博弈优化模型,例如让 10 辆搭载同一模型的虚拟车在复杂路口交互,通过奖励函数(如 “通行效率高 + 无碰撞”)强化优质决策。
实车部署与反馈:初期以 “影子模式” 运行(模型输出与人类驾驶对比,不直接控制车辆),收集接管数据(如人类纠正模型错误的场景)作为负样本。将实车数据回灌至闭环仿真,迭代优化模型,形成 “虚拟训练→实车验证→数据回传→再训练” 的闭环。
端到端辅助驾驶是大模型技术在具身智能领域的典型应用,其发展路径印证了 “从分立式到一体化”“从规则驱动到数据驱动” 的技术规律。目前,行业仍面临三大挑战:模型幻觉的抑制、虚拟与真实世界的域对齐、多安全系统的协同决策。但随着大模型能力的提升与仿真技术的成熟,完全端到端(Photon-to-Pedal)的实现已不再遥远。正如 Andrej Karpathy 所言,未来的辅助驾驶系统或将是 “一个融合多模态输入、遵循交通规则的超级智能体”,而这一目标的达成,需要 “仰望星空” 的技术愿景与 “脚踏实地” 的工程落地相结合。
本文地址:https://auto.gasgoo.com/news/202507/15I70429077C106.shtml
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921














