

大模型训练中的核心指标,特别是在车端应用中的挑战与机遇,强调数据、算力和模型结构的协同作用。本篇推文围绕大模型与车端模型的量级定义、数据采集要求、超算资源需求、业务投入成本、Transformer原理、人工智能发展、数据驱动逻辑以及人机交互等主题展开,系统性地呈现技术演进与产业化实践。
一、大模型与车端模型的基本概念区分
大模型通常指参数量达到千亿级别的模型,例如ChatGPT等代表性系统,其核心特征在于庞大的架构规模和高算力需求。车端模型则被定义为端到端模型,参数量一般控制在1亿至3亿之间,而图形或局部业务模型的顶配参数量约为六千多万。这种量级区分至关重要,避免滥用“大模型”概念,尤其在“大模型上车”的规划中。短期内,将大模型部署到车端并进行迭代训练面临巨大挑战,因为大模型的训练和优化在车端环境中实现极为困难。即便技术上可行,也缺乏实际意义,因为无法进行有效更新和优化,反而增加冗余成本。这一认知有助于行业聚焦实用技术路径,而非盲目追求概念炒作。

二、数据采集的量级与质量核心要求
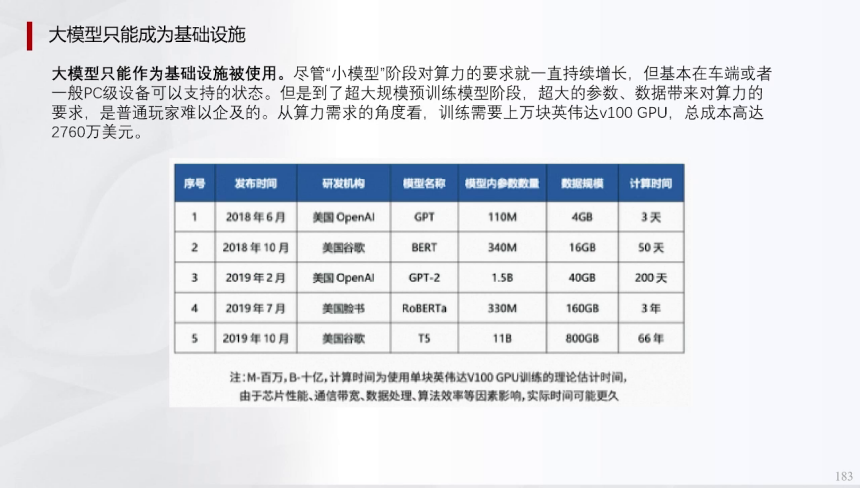
实现量产级别辅助驾驶需达到百万级数据量,这通常需要数月采集周期,涉及多车辆协同工作,以确保数据覆盖广度和密度。单个量产项目(车型)约需700小时数据,相当于120车天或3辆车总采集时间2个月的最低要求。公司级别多个项目的数据量则上升至千万甚至亿级,但数据量并非唯一指标,数据质量同样关键。
高质量数据需经过清理、标注等配套服务处理,动态数据维护量级通常在10亿至100亿之间。数据质量直接影响模型泛化能力,例如视觉感知算法需100万帧/单相机数据,Lidar需200万板数据,预测和规划则分别需5万bag和Ew bag量级。投入费用上,百万级与亿万级属于不同量级,当前行业多仅达百万级别,而特斯拉凭借海量数据积累(如30亿英里里程)构建了显著壁垒。

三、超算服务器的规模与硬件瓶颈
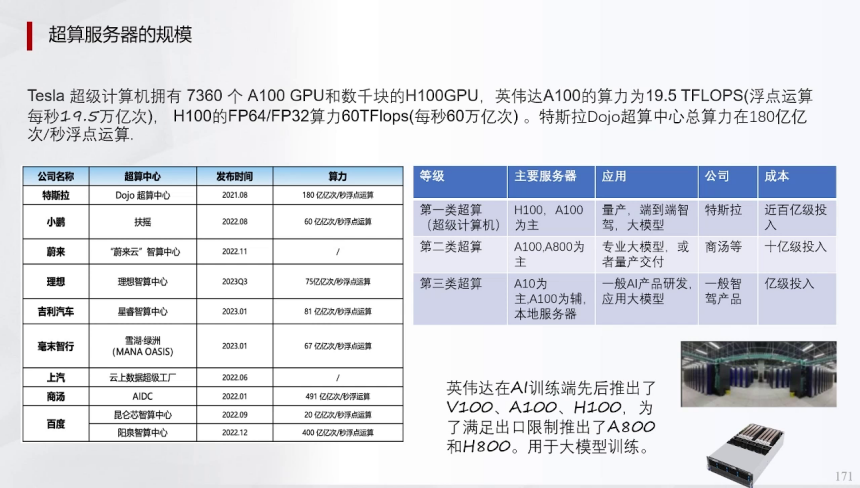
大模型训练依赖高性能超算服务器,而非民用GPU如4090,因为超大模型(如英伟达H100、A100)在并行化处理、集群通讯交换速度等方面有特殊设计。民用GPU仅适用于小模型训练,而大模型需A100(算力19.5TFLOPS)或H100(FP64/FP32算力60TFlops)等专业硬件。
特斯拉Dojo超算中心总算力达180亿亿次/秒浮点运算,国内企业则依赖技术禁运前的库存货(如商汤等)。训练资源不仅用于模型迭代,还包括高并发仿真运行,这突显算力的核心地位。超算中心分为三级:第一类如特斯拉使用H100/A100,投入近百亿;第二类以4100AAC为主,投入十亿级;第三类以/10和A100为辅,投入亿级。硬件瓶颈成为技术卡脖子问题,影响端到端模型的实际部署效率。
四、业务投入与资源消耗的量化分析
辅助驾驶业务的年投入分三级:一般量产业务需百万级别,高阶辅助驾驶需千万级别,量产大模型则需亿级别资源。具体来看,一般业务数据量约1PB(1PB年成本约100万),配套GPU服务器如V100需3台,年使用费18万左右;高阶业务数据量达10PB(年成本1000万),服务器需300台,年使用费1500万;

大模型级数据量至100PB(年成本1亿),服务器需7000台,年使用费2亿。成本不仅包含硬件,还涉及电力消耗、散热、控温及机箱安全等运营开销。随着规模扩大,租用云服务比自建更合理,除非企业财力雄厚。特斯拉的成本控制策略并非仅为盈利,而是构建数据壁垒,通过降价扩大车辆规模(如从高端定位转向平民车),从而积累竞争优势。
五、Transformer模型的核心原理与跨域应用
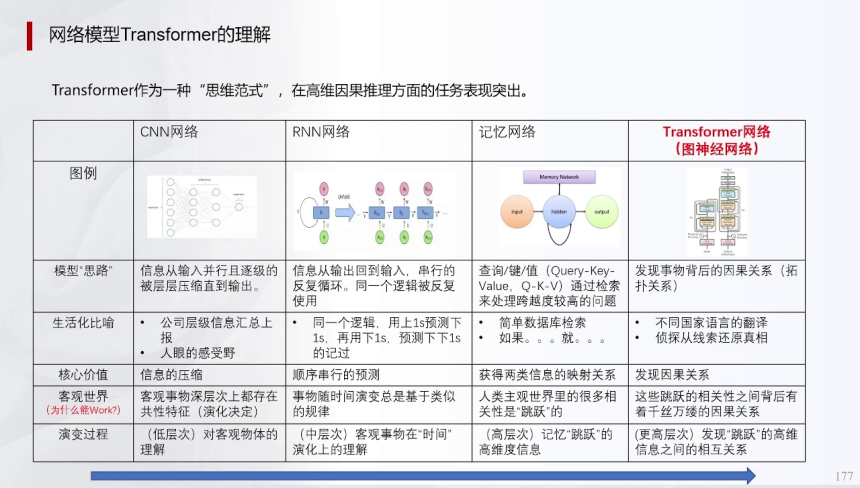
Transformer作为一种思维范式,在高维因果推理任务中表现卓越,打破了CNN、RNN和记忆网络的局限。其基础结构包含查询(Q)、键(K)、值(V)三部分,通过注意力机制(Attention)有重点地强化信号,实现信息的高效提取。

例如,在语言翻译中,Q代表输入概念,K映射到概率分布,V输出实体结果。Transformer的跨域应用从最初的语言处理扩展到图像、语音、视频及辅助驾驶领域,成为AGI的统一路径。相比CNN(基于空间分形学,适用图像)和RNN(处理时间序列,如车辆轮速信号),Transformer融合时空维度,将过去信息统一输入并揉碎处理,支持高维逻辑映射。这种结构代表模型泛化潜力,若契合任务(如预测行人轨迹),则逼近上限能力优秀;反之则限制认知发展。
六、人工智能的演进与人机智能交互前景
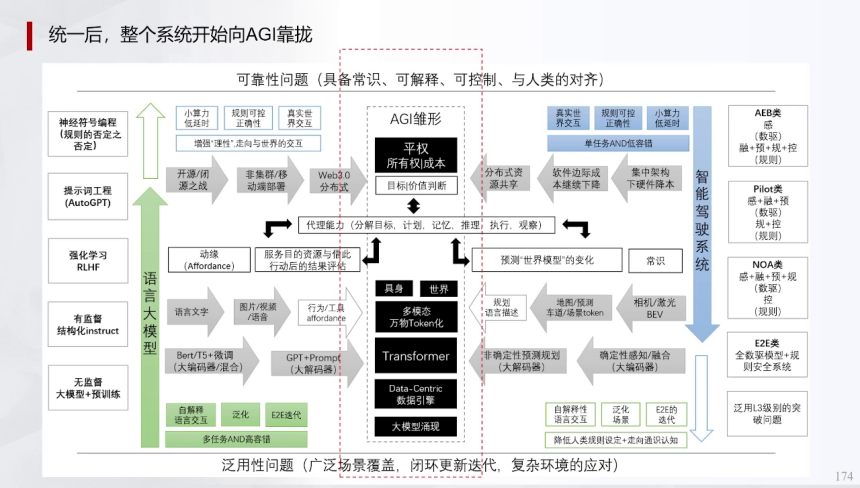
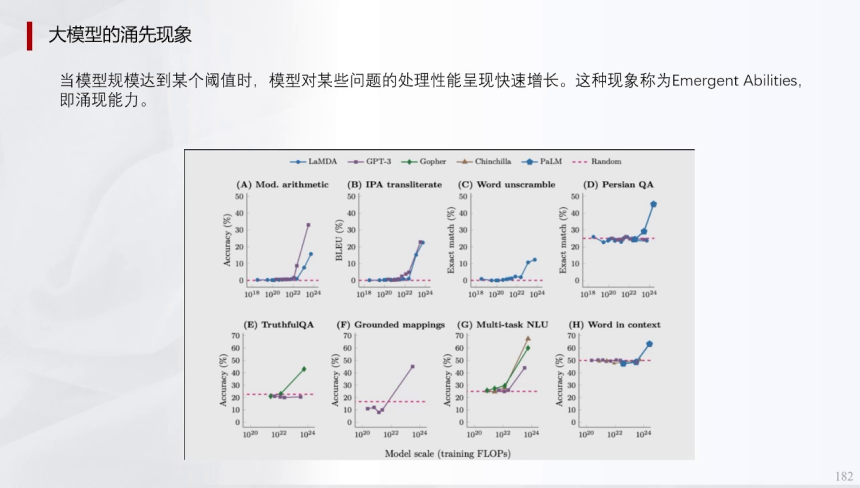
通用人工智能的演进体现AI与人的趋同化,其关键特性包括模型涌现、数据引擎、多模态处理和平权问题。涌现指模型通过高维数据压缩实现“悟性”跃升,例如特斯拉世界模型旨在精简物理规律至核心信息量。
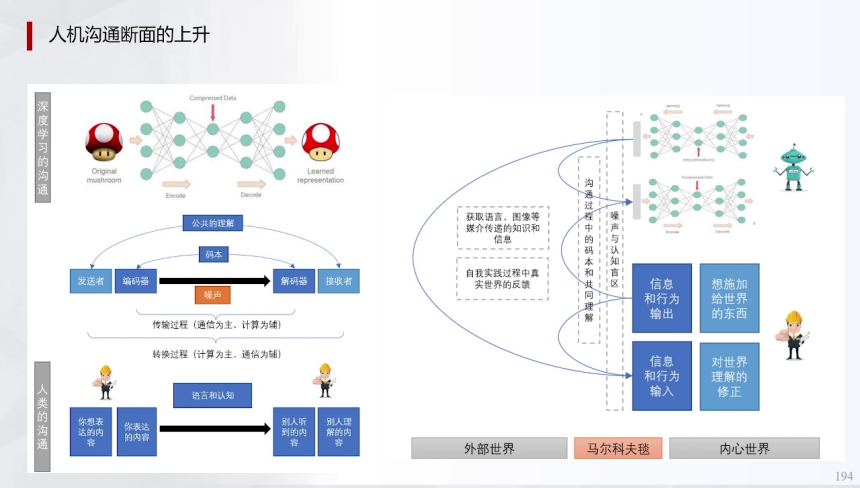
AGI发展中,人机交互断面上升:传统沟通依赖工程师编码,而现代语言模型使机器人认知维度对等,支持意图级对话。沟通模型要素包括发送者、编码器、噪声信道、解码器和接收者,需共享码本(如语言共识)和共同理解。AGI的可靠性(如安全对齐)与泛用性(场景覆盖)需平衡,类似人类处理确定性与不确定性的冲突。未来,机器可能在创新领域超越人类,因大模型(如GPT)擅长发散思维,通过提示词工程生成创意方案。
七、数据驱动与模型演进的套娃逻辑
数据驱动(Data Centric)逻辑强调数据质量决定认知上限,模型结构(如Transformer)则代表固化思维方式。从GPT1到GPT4,模型结构未变,但数据引擎优化(如提示词工程),允许大模型自我生成样本,再经人类收敛后反馈训练,形成套娃式迭代。
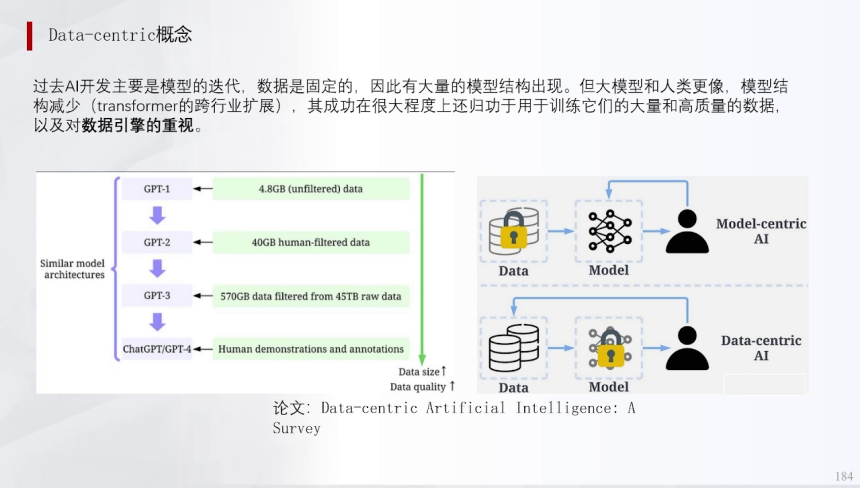
这种模糊数据与模型界限,如生成式方法(模型合成数据)与检索式方法(数据驱动模型)互补。训练过程类似柏拉图式反讽:教师提供方法论,学生(模型)通过潜力(结构优势)在数据扩充后超越教师。例如,在辅助驾驶中,高质量多维度数据(如不同路况样本)加速模型涌现,但人类在认知维度上仍具优势,能将复杂信息压缩至公式级智慧。
八、成本控制与数据规模的战略意义
成本控制的核心在于扩大数据规模以构建壁垒,特斯拉通过降价策略(从高端车转向平民车)积累30亿英里数据,远超国内车企。这一战略类似教育投资:更多车辆提升测试集与真实事件的匹配度,增加corner case覆盖概率,从而强化产品力。
但数据量非唯一指标,需结合算法优化。投入上,高阶辅助驾驶年成本达千万级别,而大模型级需亿级资源。算力消耗在仿真和训练中显著,电力、散热等运营成本随规模上升。国内企业需合理规划资源,避免盲目建超算,同时应对硬件禁运挑战。未来,数据引擎将推动辅助驾驶从百万级向亿级演进,但需平衡可靠性与范围性,确保技术落地可行。
大模型训练将深化跨模态整合能力,进一步打通语言、视觉与辅助驾驶的协同架构;超算硬件自主化进程加速,推动国产替代方案在HPC场景的落地验证;数据驱动范式持续进化,通过合成数据与真实场景的闭环校验提升模型泛化效率;成本控制策略聚焦算力复用与边缘计算,实现亿级数据规模下的资源最优配置;人机协作向意图级交互纵深发展,在确保可靠性的前提下探索辅助驾驶的认知对齐新机制。
本文地址:https://auto.gasgoo.com/news/202507/15I70429038C106.shtml
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921














