一、芯片SoC选型差异
在芯片系统级芯片(SoC)选型与域控设计领域,应用场景的差异会导致选型策略大相径庭。以自动驾驶和智能座舱这两个典型场景为例,便能清晰地看到这种差异。
在自动驾驶场景中,芯片选型有着特定的需求。若要实现自动驾驶功能,神经网络处理单元(NPU)必不可少,因为自动驾驶高度依赖对环境的感知,NPU在图像识别、目标检测等感知任务上具有强大的处理能力。同时,数字信号处理器(DSP)或空间处理器(SP)也可能被选用,用于图像的处理工作,对摄像头采集到的图像进行优化、分析等操作。在某些情况下,中央处理器(CPU)也不可或缺,负责处理规划、决策等逻辑任务,但图形处理器(GPU)并非是必需的选型,具体取决于自动驾驶系统对图形处理的需求程度。
而在智能座舱场景下,芯片选型则呈现出不同的侧重点。智能座舱主要围绕人机交互和多媒体娱乐功能展开,虽然不需要AI芯片和NPU进行复杂的智能计算,但CPU作为整个系统的核心控制单元,是确保系统稳定运行和各项功能流畅实现的关键。此外,由于智能座舱涉及到大屏幕显示以及各种图形化界面的呈现,GPU能够高效处理图形渲染任务,为用户带来流畅、绚丽的视觉体验,所以GPU成为了智能座舱芯片选型中的重要一环。
由此可见,芯片SoC的选型完全取决于产品的应用场景和具体功能需求。无论是主机厂开发新车型,还是供应商为汽车电子系统提供解决方案,都必须紧密围绕产品目标来确定芯片选型策略,以确保产品能够满足市场需求,具备良好的性能和竞争力。
二、可编程逻辑器件与GPU对选型影响
在当前的芯片市场中,可编程逻辑器件的应用趋势对芯片选型产生着重要影响。现场可编程门阵列(FPGA)因其具有灵活可编程的特性,在许多应用场景中得到了广泛应用。特别是在NPU的实现上,FPGA展现出了独特的优势。与专门定制的NPU相比,基于FPGA开发的可编程NPU在成本方面具有显著优势,尤其适用于产量较小的项目。如果产品的产量仅为一千左右,选择基于FPGA开发NPU,既能节省开发时间,又能降低开发成本,是一种经济高效的选择。
然而,当产量大幅提升,达到百万级甚至更高数量级时,情况则有所不同。随着产量的增加,定制化NPU的成本优势逐渐显现。定制化NPU是根据特定的应用需求和算法进行设计的,能够在硬件层面实现高度优化,从而在大规模生产时降低单位成本。因此,对于产量较大的产品而言,选择定制化NPU能够在保证性能的同时,有效控制成本,提升产品的市场竞争力。
再看GPU在AI芯片市场中的表现。近年来,GPU在AI芯片市场的份额呈上升趋势,到2022年已达到58%。这一现象的背后,是GPU自身强大的并行处理能力在发挥作用。以英伟达的产品为例,其GPU拥有大量的计算核心,如能实现2048个线程并行处理,且这些线程都具备强大的浮点运算能力,对于简单的加减法运算更是轻松应对。凭借这种卓越的并行处理能力,英伟达在推广其Orin系列产品时,强调GPU可直接用于AI计算,无需专门设计NPU。这意味着在一定程度上,GPU对NPU的功能具有替代作用,尤其是在处理大规模数据并行计算任务时,GPU的优势更加明显。这一特性也使得在芯片选型过程中,开发人员需要综合考虑GPU和NPU的性能、成本以及应用场景的具体需求,做出更为合理的选择。
三、自动驾驶流水线与芯片选型关系
自动驾驶的实现依赖于一套复杂的技术流程,即自动驾驶流水线(pipeline),这一流程与SoC选型紧密相关。在自动驾驶流水线中,传感器处于最前端,负责采集外界环境信息,主要包括摄像头、雷达(毫米波雷达、激光雷达)、全球定位系统(GPS)等,这些传感器就如同车辆的“眼睛”和“耳朵”,为车辆提供了感知外界的能力。
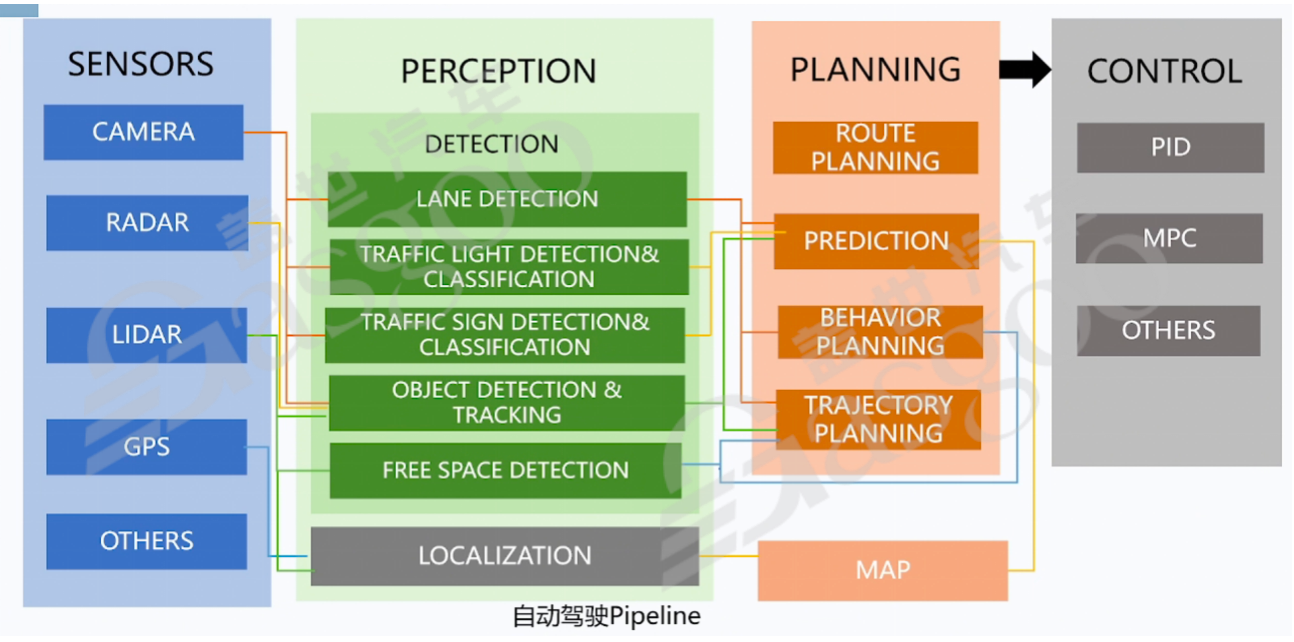
在感知环节,系统需要对传感器采集到的数据进行处理和分析,以识别车道线、交通信号灯、道路标识牌、车辆、行人等目标物体,并确定车辆周围的可行驶空间。在这个过程中,DSP发挥着重要作用,它能够对图像数据进行快速处理,提取关键特征信息。同时,GPU也会参与其中,利用其并行处理能力加速目标物的聚类和感知任务,提高感知的准确性和实时性。
规划与控制环节是自动驾驶的核心部分,其中规划主要负责根据感知结果和车辆的目标,制定行驶路线和轨迹。这包括全局路径规划,确定车辆从起点到终点的大致路线;以及局部路径规划,根据实时路况和障碍物情况,对全局路径进行调整和优化,确保车辆能够安全、高效地行驶。在规划过程中,CPU承担了主要的计算任务,它根据各种算法和模型,对大量的数据进行分析和处理,做出合理的决策。
控制则是根据规划结果,通过执行相应的算法来控制车辆的行驶。常用的算法有比例-积分-微分控制(PID)和模型预测控制(MPC)等,这些算法根据车辆的当前状态和目标状态,计算出合适的控制量,如油门开度、刹车力度、转向角度等,从而实现对车辆的精确控制。在这个过程中,CPU同样发挥着关键作用,确保控制指令能够准确、及时地发送给车辆的各个执行机构。
通过对自动驾驶流水线的分析可以看出,不同环节对芯片的需求存在差异。在前端的感知环节,由于数据量庞大且需要实时处理,更依赖于具有强大并行处理能力的NPU和GPU;而在规划和控制环节,由于涉及到复杂的逻辑运算和决策制定,CPU则成为了主要的处理单元。这就要求在进行SoC选型时,充分考虑自动驾驶各个环节的功能需求,合理选择芯片,以确保整个自动驾驶系统的性能和可靠性。
在一些先进驾驶辅助系统(ADAS)的预控制器中,选型策略会根据实际需求进行调整。由于GPU的成本相对较高,对于一些纯视觉的ADAS系统,尤其是对成本较为敏感的产品,开发人员可能会选择价格更为亲民的NPU来替代GPU的部分功能。NPU在处理图像识别、目标检测等任务时,虽然在图形渲染能力上可能不如GPU,但在特定的AI计算场景下,能够以较低的成本提供足够的算力支持。
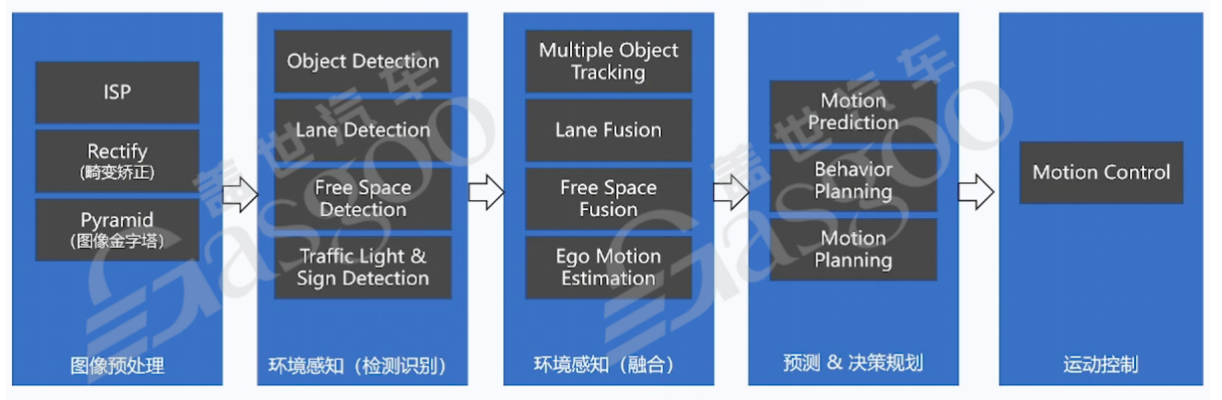
以视觉处理流程为例,在图像进入系统后,首先会经过图像信号处理器(ISP)进行预处理,包括畸变矫正、图像金字塔构建等操作。这些操作旨在优化图像质量,为后续的目标物感知和检测提供更好的数据基础。经过预处理的图像会进入环境感知阶段,在这个阶段,系统会对目标物进行感知、检测和识别,如识别车辆、行人、交通标志等。随后,不同传感器的数据会进行融合,将摄像头、雷达等多种传感器的数据进行综合分析,以提高对环境的感知精度。最后,通过环境重构,基于融合后的数据构建出车辆周围的环境模型,为后续的决策和控制提供依据。
在这个过程中,不同的任务会分配给不同的芯片进行处理。例如,在图像预处理阶段,大部分工作可以由专用芯片或ISP来完成;在目标物感知和检测环节,NPU能够发挥其强大的AI计算能力,快速识别出各种目标物体;而在数据融合和环境重构阶段,CPU则负责协调和处理复杂的逻辑运算。这种精细的分工能够充分发挥不同芯片的优势,在保证系统性能的前提下,实现成本的优化。

四、芯片算力评估及相关因素
在SoC选型过程中,算力评估是一个至关重要的环节,它直接关系到所选芯片是否能够满足产品的性能需求。以TDA4VM芯片为例,其各项性能指标具有一定的代表性。
TDA4VM的GPU算力为100 GFLOPs,AI算力为8 TOPS。与市场上其他主流芯片相比,英伟达的部分芯片AI算力可达到240-250TOPS,高通的8650芯片AI算力约为50-80TOPS。可以看出,TDA4VM的AI算力相对较低,但这是由于其推出时间较早,当时芯片算力的竞争还未达到如今这般激烈的程度。
在内存方面,TDA4VM的内存带宽为17GB/s,这一指标对AI和GPU的性能有着重要影响。如果内存带宽不足,数据无法及时传输到计算单元,会导致芯片的算力利用率降低,从而影响整个系统的性能。
TDA4VM的CPU采用2个A72核,总算力为25KDMIPS。而英伟达的部分产品采用12个A78核,算力可高达124KDMIPS,相比之下,TDA4VM的CPU算力也相对较弱。
此外,TDA4VM的R核是用于实时处理的芯片,被应用于安全岛设计。其R核算力较高,能够达到8KDMIPS或42KDMIPS,在某些情况下,开发人员可以利用R核的强大性能,无需外挂微控制单元(MCU),直接将其作为安全岛上的控制核心,从而简化系统设计,降低成本。
从芯片厂商的角度来看,在面对客户关于芯片支持能力的询问时,往往会面临一定的困境。由于芯片的实际支持能力不仅取决于自身的算力,还与客户的设计复杂度、应用场景等多种因素密切相关,所以芯片厂商很难直接给出明确的答复。为了更好地推广产品,芯片厂商通常会进行市场调研,了解当前市场上各种汽车功能(如自适应巡航控制(ACC)、自动紧急制动(AEB)、车道居中控制(LCC)等)对算力的一般需求,并向主机厂或一级供应商提供这些信息。同时,芯片厂商会强调,虽然芯片只能提供特定的算力,但只要客户能够合理地进行部署和优化,芯片是能够满足这些常见功能的算力需求的。
从开发者的角度出发,如果具有丰富的经验,在评估芯片时,可以根据芯片的各项算力指标,大致判断其是否能够满足特定自动驾驶等级的需求。例如,当看到一款芯片的CPU算力达到100KDMIPS,AI算力达到50TOPS时,结合经验可以初步判断该芯片能够满足L2+级别的自动驾驶功能需求。但需要明确的是,这只是一种基于经验的大致判断,芯片的实际性能还需要在具体的项目开发过程中,通过实际的部署和测试来确定。在实际应用中,由于不同的神经网络模型、数据处理流程以及硬件架构的差异,芯片的算力利用率会有所不同,因此实际性能可能与理论评估存在一定的差距。
在实际的芯片应用中,算力利用率是一个不容忽视的关键因素,它受到多种因素的综合影响。通常情况下,芯片手册上标注的算力(TOPS)是理论值,并非整个硬件系统在实际运行中的真实算力。在实际运行过程中,由于各种因素的制约,真正能够被有效利用的算力可能只有理论值的30%,甚至更低。
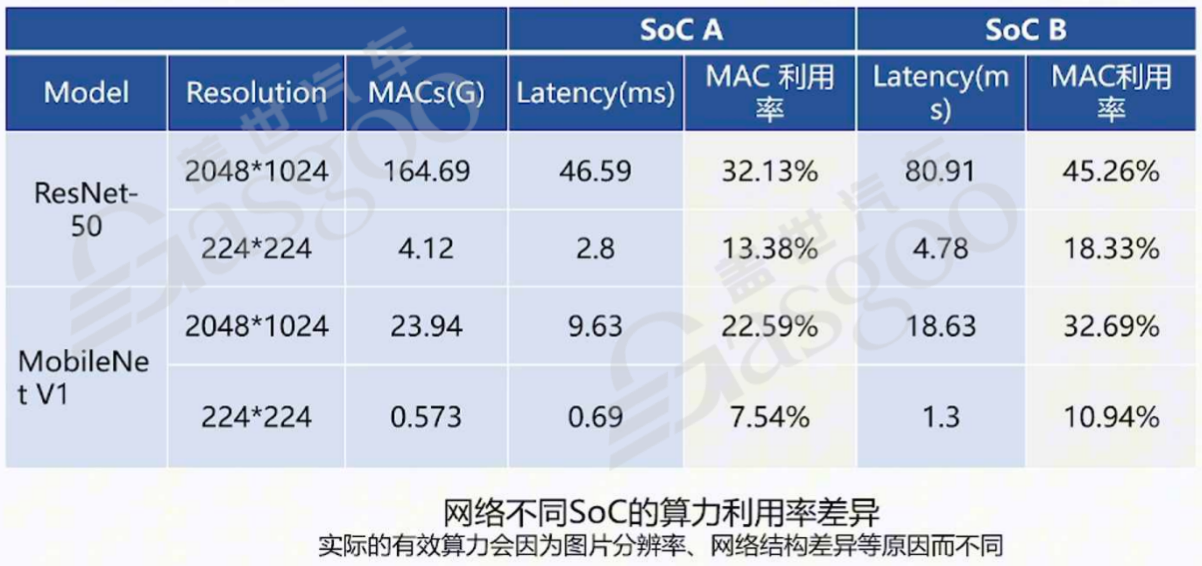
计算架构对算力利用率有着重要影响。NPU作为高度定制化的计算架构,对于不同的网络结构,其利用率存在显著差异。以ResNet和MobileNetV1这两种常见的神经网络为例,在使用不同厂家的SoC进行测试时,发现A厂家的SoC在处理分辨率为2048×1024的图像时,针对ResNet网络的算力利用率为32.13%,而B厂家的SoC在相同条件下的算力利用率则达到了45.26%。这表明不同厂家的SoC在应对相同的网络结构和图像分辨率时,算力利用率可能会有较大的差距。同时,当图像分辨率发生变化时,如降低到224×224,A厂家和B厂家SoC的算力利用率也会相应改变,分别变为13.38%和18.33%,这进一步说明了网络结构和图像分辨率对算力利用率的影响。
存储带宽也是影响算力利用率的关键因素之一。存储带宽决定了数据搬运的速度,如果存储带宽无法跟上计算速度,数据就无法及时传输到计算单元,导致计算单元出现空闲等待数据的情况,从而使算力利用率大打折扣。这就好比工厂的生产速度很快,但原材料的运输速度却跟不上,工厂只能间歇性地生产,无法充分发挥其生产能力。
在芯片选型过程中,开发者需要充分考虑这些因素。如果产品对实时性要求较高,更偏向于快速响应,那么在选择芯片时,就需要优先考虑那些处理速度快、延迟低的芯片,即使其算力利用率可能相对较低;反之,如果产品对运算量的要求较大,对响应时间的要求相对宽松,那么可以选择算力利用率较高的芯片,以充分利用芯片的计算资源。通过综合权衡这些因素,开发者能够选择最适合产品需求的芯片,提高系统的整体性能。
内存带宽在芯片系统中起着至关重要的作用,它直接关系到CPU、NPU、GPU等处理器和加速器的运行效率。这些处理器和加速器在执行指令的过程中,不仅需要从内存(DDR)中读取指令,还需要频繁地读写数据。在多核并发运行的情况下,多个核心会同时对DDR进行访问,如果DDR带宽不足,就会成为整个SoC系统的瓶颈,限制各处理器和加速器的性能发挥。
五、其他关键因素及车企芯片应用案例
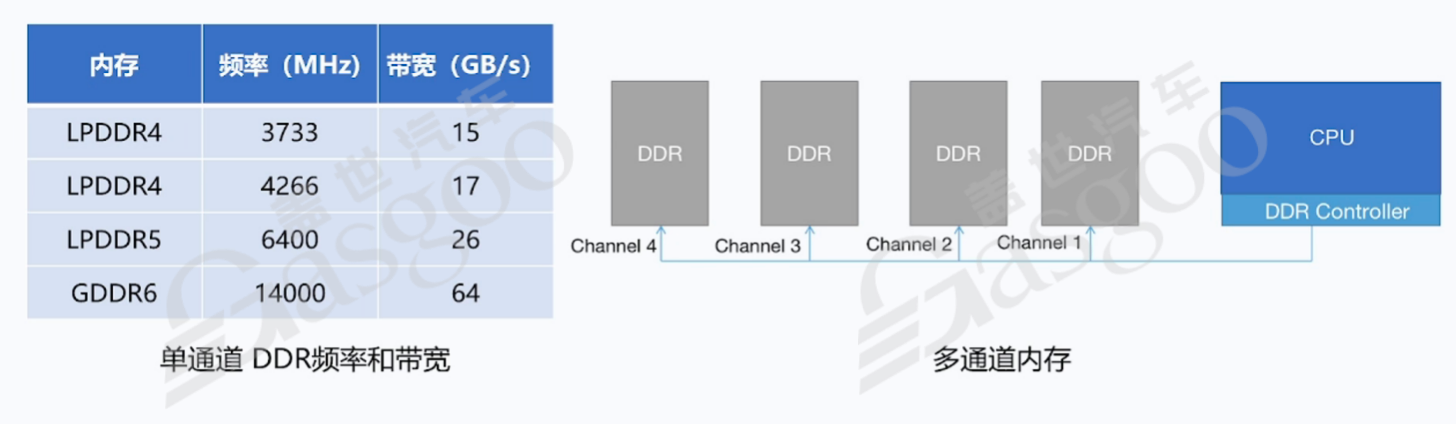
内存带宽的大小与多个因素相关,其中DDR的频率和通道数是两个关键因素。以常见的低功耗双倍数据速率同步动态随机存储器(LPDDR)为例,LPDDR4的频率范围一般在3000多兆赫兹到6000多兆赫兹之间,对应的带宽为15-17GB/s;而LPDDR5的频率有所提升,带宽也相应增加到26GB/s,相比LPDDR4有了显著的提升。此外,DDR的通道数也会影响总带宽,理论上双通道DDR带宽是单通道的2倍。如果SoC只连接一个通道的DDR,那么对DDR的访问是单通道串行的,数据传输速度相对较慢;而如果同时连接4通道DDR,4个通道可以并发访问,能够大大提高DDR带宽,满足系统对数据传输速度的更高要求。
在自动驾驶领域,随着车辆智能化程度的不断提高,对内存带宽的需求也在迅速增长。以800万像素摄像头为例,其所需的数据带宽可以通过公式计算得出:3840×2160×20bit×30fps×1.5(tolerance)≈0.933GB/s。如果车辆配备了11路800万像素的相机,仅摄像头数据传输所需的内存带宽就约为10GB/s。再考虑到激光雷达点云数据等其他数据的传输需求,整个系统所需的内存带宽会更大。例如,L5级别的自动驾驶车辆,其内存带宽需求能够达到约560GB/s,这是一个非常庞大的数字,对内存系统提出了极高的要求。
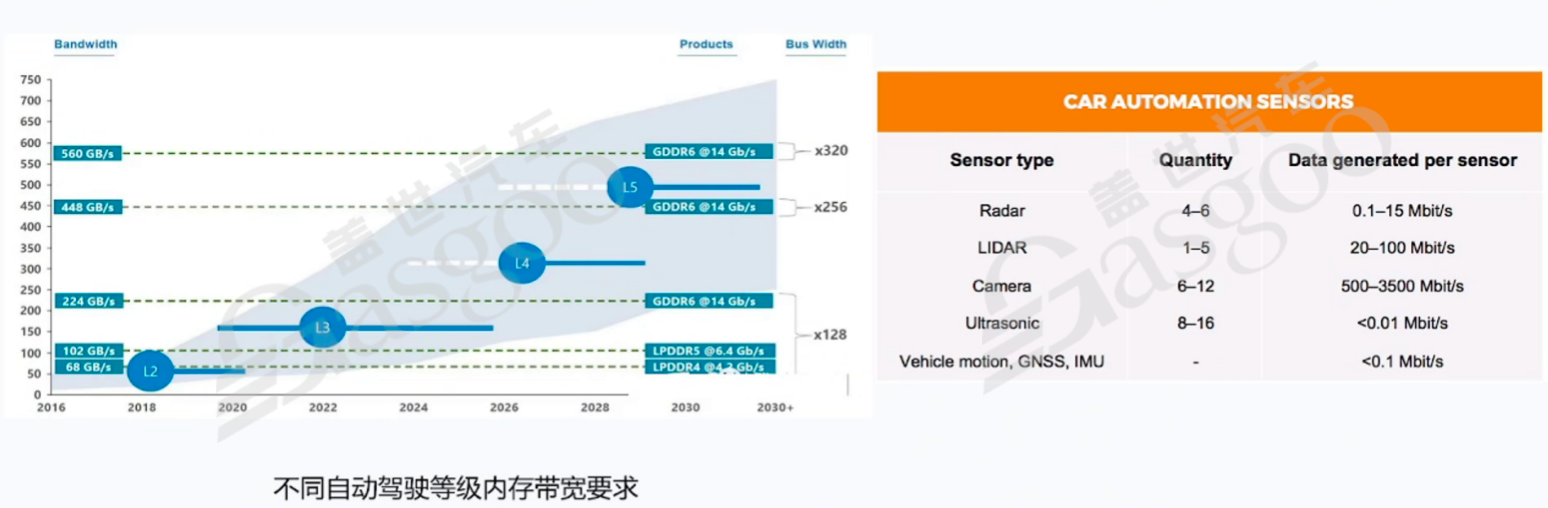
如果在内存选型时选择了不匹配的内存,如使用了带宽较低的老款内存,就无法满足数据传输的需求,会导致数据堵塞,影响整个系统的性能。内存带宽的发展需要整个行业的协同推进,包括内存厂商(如美光)不断提升内存的性能,芯片厂商(如英伟达)优化芯片与内存的接口设计,摄像头厂商(如索尼)提高数据传输效率,以及系统集成商和主机厂在系统架构设计上充分考虑内存带宽的需求,推动电子电器架构的升级,只有这样,才能满足自动驾驶等新兴应用对内存带宽的严格要求。
芯片的功耗与温度控制是SoC选型过程中不可忽视的重要因素,它们对车辆的性能、安全性以及用户体验都有着深远的影响。
芯片功耗过高会引发一系列问题。对于新能源汽车而言,功耗的增加意味着耗电量的大幅上升,这会直接影响车辆的续航里程。例如,在车辆开启哨兵模式时,芯片需要持续运行以监控周围环境,若芯片功耗过高,会导致电池电量快速消耗,使车辆的续航能力大打折扣,给用户带来不便。
芯片功耗还会对车辆的结构设计和散热系统产生影响。当芯片功耗较大时,会产生大量的热量,如果不能及时有效地散热,芯片温度会持续升高,进而影响芯片的性能和稳定性,甚至可能导致芯片损坏。为了保证芯片在适宜的温度范围内工作,需要采取相应的散热措施。对于低功耗芯片,如功耗在15-30瓦左右的芯片,风冷散热方式通常就能够满足需求,通过风扇将热量带走,实现芯片的降温。然而,对于一些高算力芯片,如小鹏汽车使用的英伟达芯片,其算力拉满时功耗可能高达一百瓦以上,此时风冷散热就显得力不从心,需要采用主动散热方式,如风扇散热和水冷散热相结合的方式。
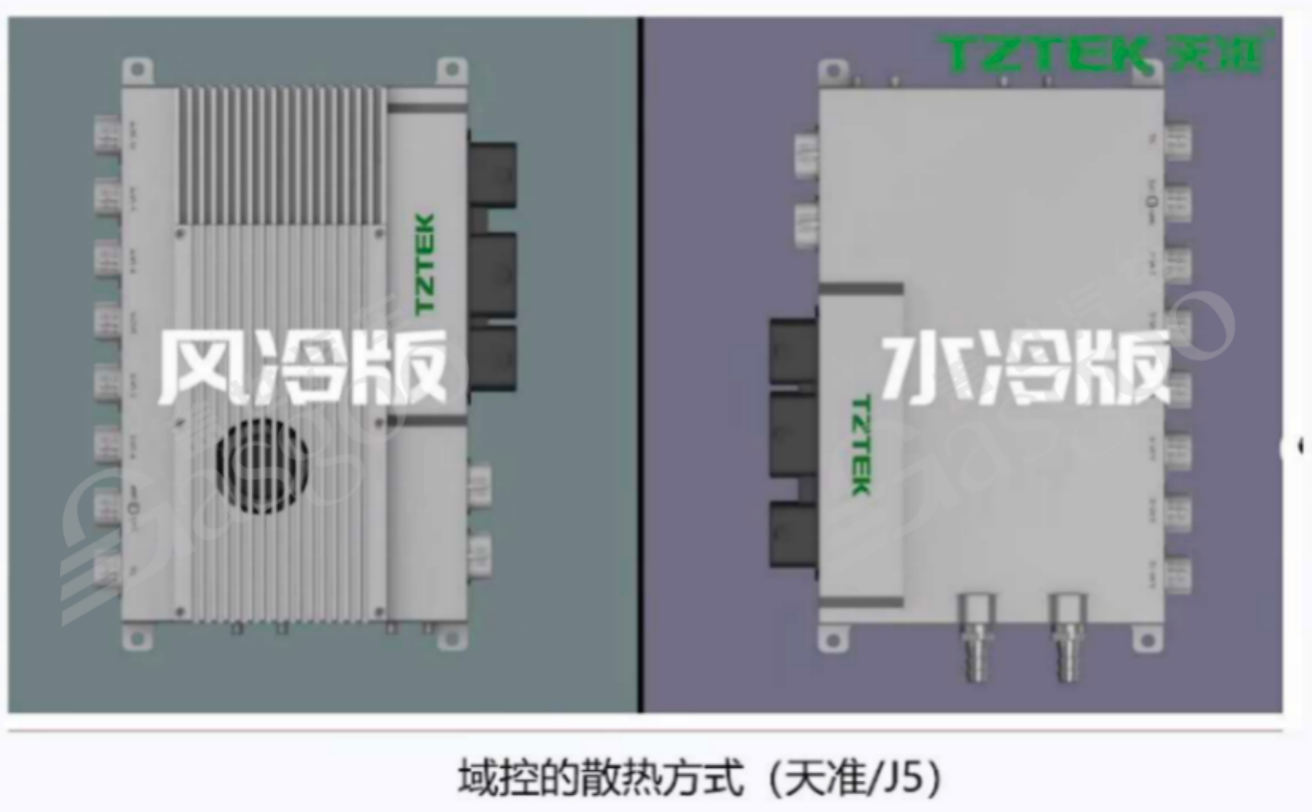
在采用水冷散热时,为了实现对温度的精确控制,需要集成专门的散热软件。传统的固定水冷方式无法根据芯片温度的变化实时调整水冷流量,可能导致芯片温度过高或过低,影响芯片性能。而通过温度监控软件,可以实时监测芯片温度,并根据温度变化自动调节水冷阀门的开度,控制水冷流量,使芯片始终保持在合适的温度范围内,确保芯片的稳定运行。
一般来说,当芯片算力达到100 TOPS以上,功耗超过60瓦时,为确保控制器正常工作,就需要采用主动散热措施。在实际的域控设计中,开发人员需要根据芯片的功耗特性,合理选择散热方式,并结合散热软件进行温度控制,以保障整个系统的可靠性和稳定性。
在高阶自动驾驶领域,由于传感器的种类和数量繁多,包括车载摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、惯性测量单元(IMU)、车联网(V2X)模块等,这些传感器都需要与SoC进行数据交互,因此接口资源成为了SoC选型时必须重点考虑的因素。
不同类型的传感器通过不同的接口接入SoC。例如,视频摄像头通常通过JMCL或低压差分信号(LVDS)接口接入,LVDS接口具有传输速率高、抗干扰能力强的特点,能够满足摄像头高速数据传输的需求;毫米波雷达一般通过KSD接口接入,确保雷达数据能够准确、快速地传输到SoC;激光雷达则多采用以太网接口,这是因为激光雷达产生的数据量巨大,以太网的高带宽特性能够保证数据的高效传输。
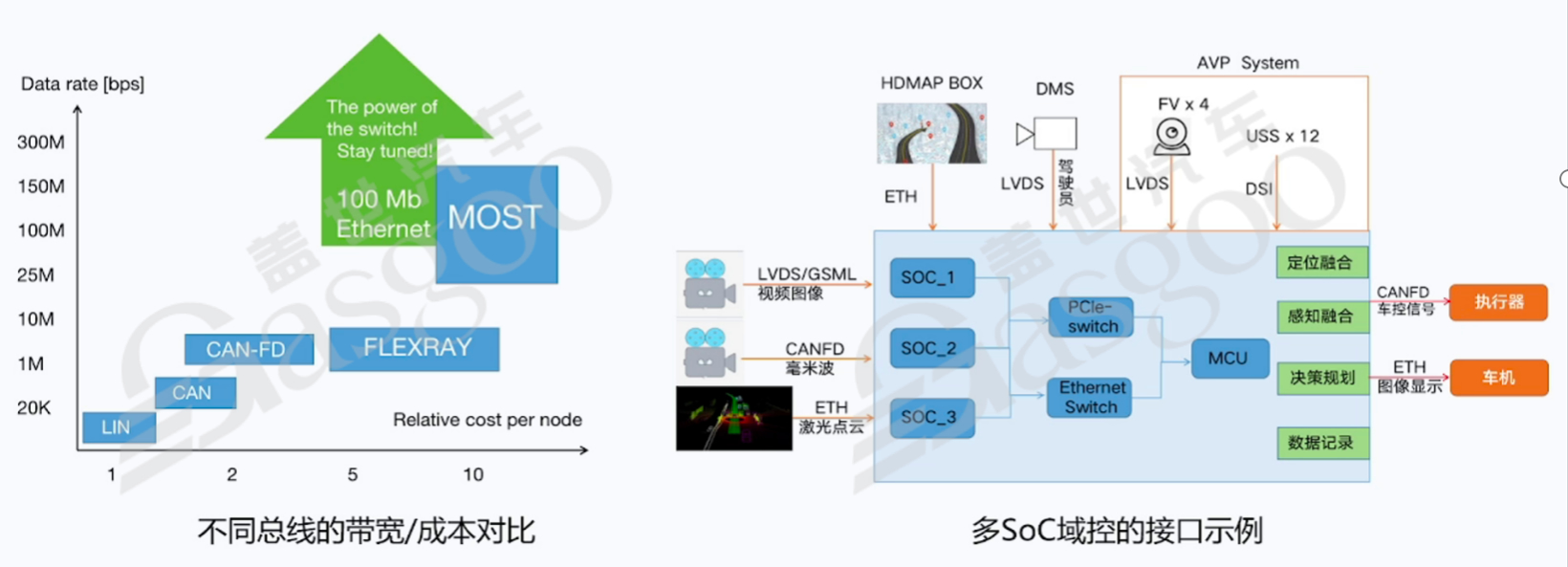
在数据传输过程中,如果接口带宽不足,会导致数据堵塞,影响整个自动驾驶系统的性能。例如,早期的控制器局域网(CAN)总线标准,每个报文只有八个字节,其传输速率较低,难以满足自动驾驶大量数据的实时传输需求。随着自动驾驶等级从L2向L3、L4甚至更高等级发展,数据量呈指数级增长,对接口带宽的要求也越来越高。如今,千兆以太网的出现为解决这一问题提供了可能,它能够满足激光点云等大数据量的传输需求,确保系统的流畅运行。
除了数据传输接口,存储接口在SoC选型中也至关重要。高清地图的存储需要较大的空间,一般约为4GB,这部分数据通常存储在嵌入式多媒体存储卡(eMMC)中,eMMC类似于计算机的硬盘,能够在车辆下线后仍然保存数据,包括地图信息、操作系统镜像等。而随机存取存储器(RAM),如双倍数据速率同步动态随机存储器(DDR),主要用于运行时数据的加载,其容量一般为4GB左右,用于存储高精地图以及融合预测处理过程中产生的数据。此外,闪存(Flash)常用于微控制单元(MCU)的程序存储,容量相对较小,一般为32MB。
在通信总线方面,通用输入输出接口(GPIO)用于实现通用的输入输出功能;高速串行计算机扩展总线标准(PCle)主要用于SoC与MCU之间的高速信息传输,能够满足大量数据快速传输的需求;串行外围设备接口(SPI)则适用于SoC与其他设备之间的简单、快速但非海量数据的通信。不同的通信总线在自动驾驶系统中各司其职,共同保障数据的可靠传输。
随着自动驾驶功能的不断升级,对接口资源的要求也在持续提高。从L2到L3、L4等级的提升过程中,不仅存储容量需求大幅增加,如存储可能需要从4GB提升到16GB甚至更高,eMMC容量也可能扩展到512GB,Flash容量可能增加到64GB,而且对通信总线的性能要求也更加严格。例如,PCle可能需要升级到4.0版本,以提供更高的传输速率;以太网可能需要支持八路千兆以太网,以满足多个传感器和设备的数据传输需求;CANFD总线的数量可能增加到12路,以确保大量原始信号的稳定传输。这种上层应用功能的不断拓展和升级,反过来推动了底层接口技术的持续变革和发展。
新势力车企在汽车智能化发展的浪潮中,积极推动着SoC芯片的演进,其发展路线清晰地反映了汽车智能化功能不断升级的需求以及芯片技术的持续进步。
以小鹏汽车为例,其智驾产品从早期的Xpilot2.0版本逐步发展到Xpilot 5.0版本,功能实现了从L2级别的基础辅助驾驶,如简单的自适应巡航和车道保持功能,逐渐拓展到城区NOP(Navigate on Pilot,城市导航辅助驾驶)、高速NOP,再到城市自动驾驶以及局部全自动驾驶等更高级别的功能。与之相匹配的是SoC芯片的不断升级,从最初的EyeQ4芯片,到英伟达Xavier,再到双Orin X芯片。这种芯片的升级过程是为了满足智驾功能日益复杂对算力的需求,每一次芯片的更换都意味着更高的算力支持,从而能够实现更高级别的自动驾驶功能,为用户带来更加智能、便捷和安全的驾驶体验。
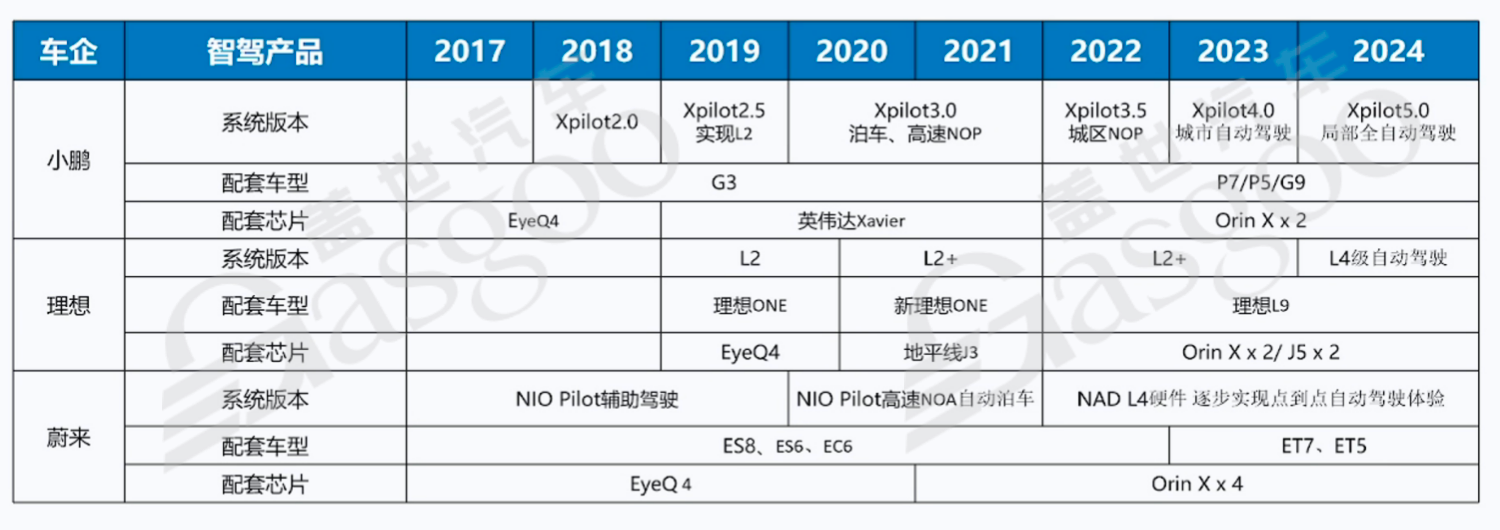
理想汽车的发展历程也呈现出类似的趋势。从理想ONE搭载EyeQ4芯片实现L2级辅助驾驶,到新理想ONE和理想L9采用地平线J3、OrinX x2或J5×2芯片,逐步提升车辆的智能驾驶能力,向更高等级的自动驾驶迈进。
蔚来汽车同样如此,从早期车型ES8、ES6、EC6配备EyeQ4芯片实现NIO Pilot辅助驾驶功能,到ET7、ET5搭载OrinXx4芯片,为实现NAD(NIO Autonomous Driving,蔚来自动驾驶)L4级硬件能力奠定基础,逐步向点到点自动驾驶体验的目标靠近。
可以看出,随着新势力车企智驾功能从L2向L4及更高等级的发展,对SoC芯片算力的要求越来越高。在这个过程中,双OrinX芯片的应用逐渐增多,这不仅是因为算力的需求,还涉及到功能安全方面的考虑。在L4级自动驾驶中,功能安全至关重要,双芯片的设计可以在一定程度上提高系统的可靠性和安全性,确保在复杂的驾驶场景下,车辆能够安全、稳定地运行。
在汽车芯片市场中,众多厂商推出了丰富多样的SoC芯片产品,以满足不同层次的市场需求。这些芯片在算力、功耗、制程以及适用等级等方面存在显著差异。
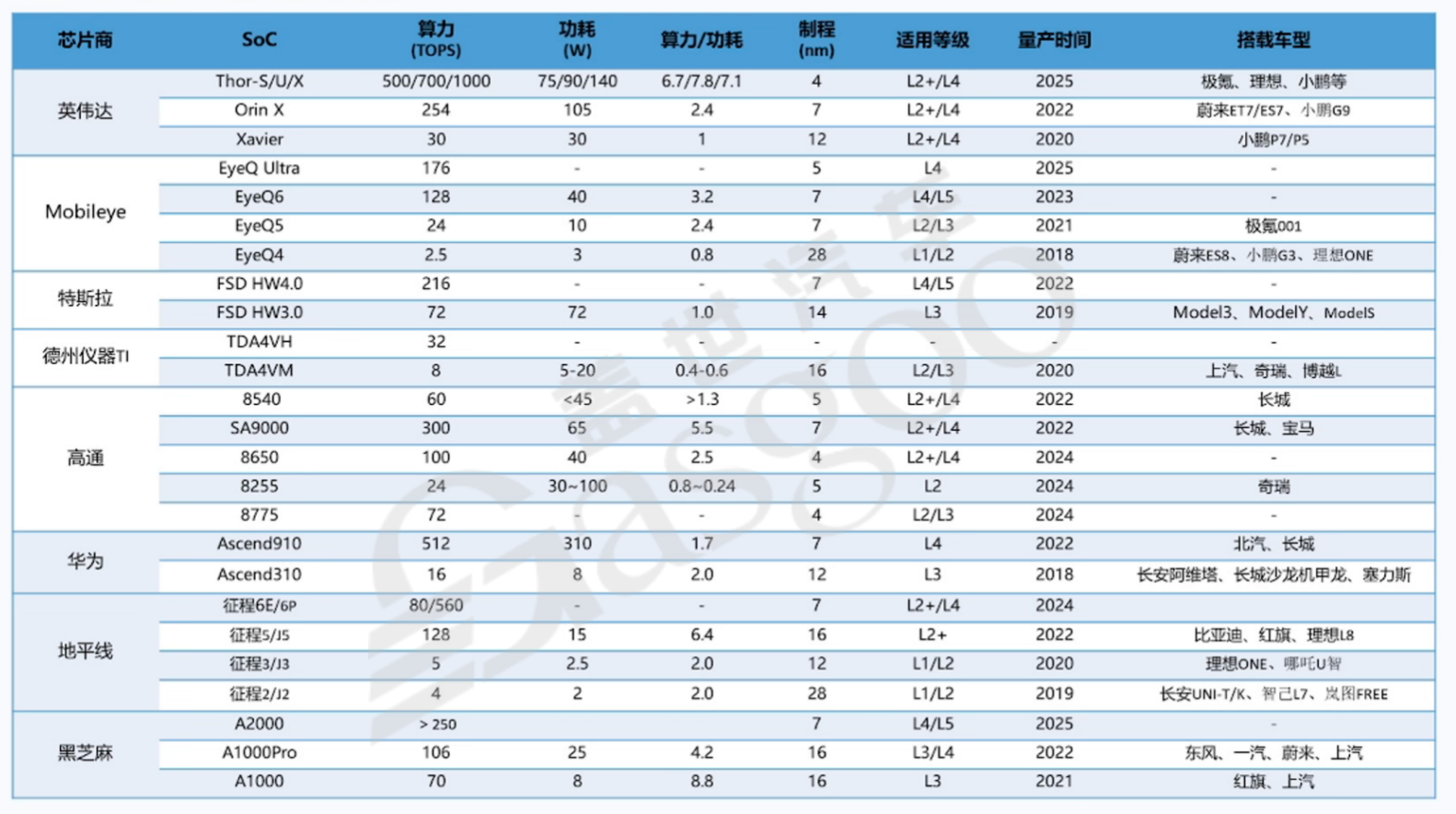
英伟达作为芯片行业的重要参与者,其产品涵盖了高、中、低不同档次。Thor系列作为高端产品,包括Thor-S/U/X,算力分别达到500/700/1000TOPS,功耗为75/90/140W,制程为6.7/7.8/7.1nm,适用于L2+/L4等级的自动驾驶场景,计划于2025年量产,将搭载于极氪、理想、小鹏等车企的车型上。Orin X则是其中端产品,算力为254 TOPS,功耗2.4W,制程7nm,自2022年量产以来,已应用于蔚来ET7/ES7、小鹏G9等车型,能够为这些车辆提供可靠的算力支持,实现较为高级的自动驾驶功能。Xavier作为低端产品,算力为30 TOPS,功耗30W,制程12nm,于2020年开始量产,在小鹏P7/P5等车型上得到应用,为车辆提供基础的自动驾驶辅助能力。
Mobileye公司的芯片产品也具有广泛的市场影响力。EyeQ Ultra算力高达176TOPS,功耗5W,计划于2025年量产,主要面向L4等级的自动驾驶市场,旨在为高度自动驾驶提供强大的计算支持。EyeQ6的算力为128TOPS,功耗40W,制程7nm,预计2023年量产,适用于L4/L5等级的自动驾驶场景,其高性能和低功耗的特点使其在高级别自动驾驶领域具有竞争力。EyeQ5算力为24 TOPS,功耗10W,制程7nm,自2021年量产,应用于极氪001等车型,能够满足L2/L3等级的自动驾驶需求,为车辆提供较为丰富的驾驶辅助功能。EyeQ4算力相对较低,为2.5 TOPS,功耗3W,制程28nm,自2018年量产以来,被广泛应用于蔚来ES8、小鹏G3、理想ONE等车型,为这些车辆实现基础的L1/L2级辅助驾驶功能提供了可能。
特斯拉自主研发的FSD(FullSelf-Driving)芯片也在自动驾驶领域占据一席之地。FSDHW4.0算力达到216 TOPS,功耗7W,适用于L4/L5等级的自动驾驶,自2022年开始应用于特斯拉的车型中,为特斯拉车辆实现更高级别的自动驾驶功能提供了核心支持。FSDHW3.0算力为72 TOPS,功耗72W,制程14nm,从2019年开始应用于Model3、ModelY、ModelS等车型,能够满足L3等级的自动驾驶需求,在一定程度上提升了车辆的自动驾驶能力。
德州仪器(TI)的TDA4VH和TDA4VM芯片主要面向中低端市场。TDA4VM算力为8TOPS,功耗5-20W,制程16nm,自2020年量产以来,已应用于上汽、奇瑞、博越L等车型,能够为这些车辆提供L2/L3等级的自动驾驶支持,以其稳定的性能和合理的成本在中低端市场具有一定的竞争力。
高通公司的芯片产品涵盖了智能座舱和自动驾驶领域。在自动驾驶方面,8540算力为60 TOPS,功耗小于45W,制程大于1.3nm,自2022年量产,主要应用于长城等车企的车型,为车辆提供L2+/L4等级的自动驾驶算力支持。SA9000算力为300 TOPS,功耗65W,制程5.5nm,虽然它被类比为独立显卡,但在自动驾驶领域也有其应用场景,可用于支持更高级别的自动驾驶功能。8650算力为100 TOPS,功耗40W,制程2.5nm,计划于2024年量产,同样适用于L2+/L4等级的自动驾驶场景,能够满足车企对中高端自动驾驶芯片的需求。8255主要定位于智能座舱SOC,算力为24TOPS,功耗30-100W,制程5nm,于2024年量产,在智能座舱领域具有较高的性能表现。8775是高通主推的舱驾一体芯片,算力为72TOPS,旨在为车企提供集成度更高的解决方案,满足车辆对座舱和驾驶域融合的需求。
华为的Ascend910算力高达512TOPS,功耗310W,制程7nm,自2022年开始应用于北汽、长城等车企的车型,主要用于支持L4等级的自动驾驶功能,展现了华为在高端自动驾驶芯片领域的技术实力。Ascend310算力为16 TOPS,功耗8W,制程12nm,从2018年开始应用于长安阿维塔、长城沙龙机甲龙、塞力斯等车型,可满足L3等级的自动驾驶需求,为车辆提供一定程度的自动驾驶辅助能力。
地平线作为国内知名的芯片企业,其征程系列芯片发展迅速。征程6E/6P算力分别为80/560 TOPS,计划于2024年量产,适用于L2+/L4等级的自动驾驶场景,具有较高的性价比,为国内车企提供了更多的选择。征程5/15算力为128 TOPS,功耗15W,制程16nm,自2022年量产以来,已应用于比亚迪、红旗、理想L8等车型,为这些车辆实现L2+级别的自动驾驶功能提供了有力支持。征程3/J3算力为5 TOPS,功耗2.5W,制程12nm,于2020年量产,在理想ONE、哪吒U智等车型上得到应用,可实现基础的L1/L2级辅助驾驶功能。征程2/12算力为4 TOPS,功耗2W,制程28nm,自2019年量产,应用于长安UNI-T/K、智己L7、岚图FREE等车型,为车辆提供基本的驾驶辅助算力保障。
黑芝麻公司的A2000算力大于250 TOPS,制程7nm,计划用于L4/L5等级的自动驾驶场景,虽然其产品相对较新,但展现出了在高端自动驾驶芯片领域的潜力。A1000Pro算力为106 TOPS,功耗25W,制程16nm,自2022年开始应用于东风、一汽、蔚来、上汽等车企的车型,可满足L3/L4等级的自动驾驶需求。A1000算力为70 TOPS,自2021年量产以来,已应用于红旗、上汽等车型,能够为车辆提供一定程度的自动驾驶辅助功能。
从这些芯片的参数对比可以看出,高端芯片与低端芯片的分水岭主要体现在算力方面。一般来说,算力在100-200 TOPS以上的芯片可归为高端芯片,能够支持高级别的自动驾驶功能,如L4及以上等级;算力在50 TOPS上下的芯片属于中端芯片,可满足L2+等级的自动驾驶需求;而算力在个位数的芯片则主要用于支持基础的L1/L2级辅助驾驶功能,属于低端芯片。在功耗方面,高端芯片由于算力较高,通常功耗也较大,一般在一百多瓦;而低端芯片功耗相对较低,可能在40瓦以下,甚至低至8瓦。制程方面,虽然芯片厂对制程的追求不断提高,但对于车企来说,更关注芯片的综合性能是否满足需求,即使芯片制程有所差异,只要能满足车辆的功能要求,依然会被选用。
在汽车行业的发展进程中,主机厂和方案商在域控设计方面展现出了各自的特点和创新。长城汽车在域控设计上,采用了高性能、高算力的异构SOC,其算力可达30KDMIPS。该域控系统配备了11路高清摄像头,能够为车辆提供丰富的视觉信息,支持更精准的环境感知和驾驶决策。同时,具备18路CANFD、4路LIN和11路车载以太网,这些丰富的通信接口确保了数据的高效传输,使车辆各个部件之间能够快速、稳定地进行信息交互。在存储方面,支持64GB的大容量存储和1GB的内存,为高清地图存储、数据处理以及系统运行提供了充足的空间。此外,其功能安全等级最高可支持ASILD,这一高标准的功能安全设计,为车辆的安全行驶提供了可靠保障,体现了长城汽车在域控设计上的技术实力和对安全性能的重视。

某方案商基于单TDA4的域控设计也具有一定的代表性。在传感器接入方面,配备了前视摄像头(200万像素,实际可能为800万像素更合理)和四路鱼眼摄像头,通过LVDS接口将图像数据传输至TDA4VM芯片。同时,支持五路毫米波雷达和12路超声波雷达接入,这些雷达通过CANFD总线与芯片进行数据交互,为车辆提供了全方位的环境感知能力。在通信方面,与T-Box之间通过以太网进行通信,以实现远程控制和数据传输功能;与座舱之间则通过LVDS进行图像透传,确保座舱能够实时显示车辆周围的环境图像。
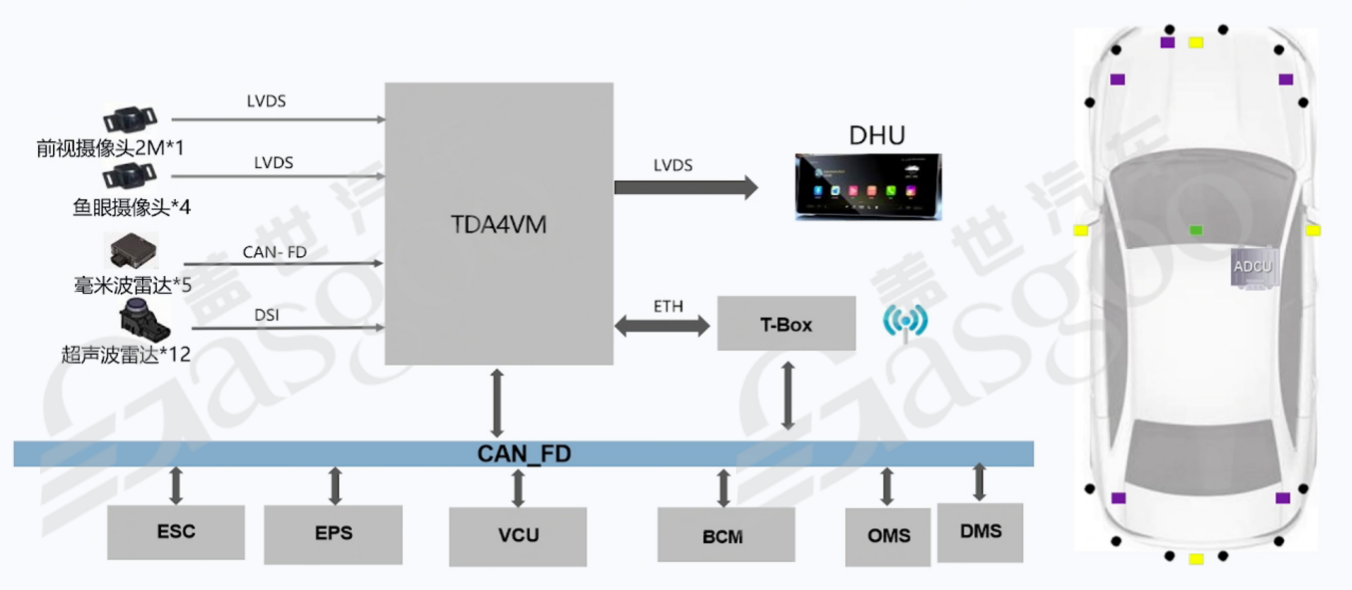
在该域控设计中,TDA4VM芯片内部集成了CPU、R核、GPU、DSP等多种功能模块。其中,安全岛部分采用了R52核(若采用英飞凌的TC397,则是基于其独立IP设计的芯片),然而,由于开发难度较大等原因,目前安全岛的资源在很多情况下未得到充分利用。如果能够充分开发安全岛资源,就有可能省去外部的MCU,从而简化系统设计,降低成本。
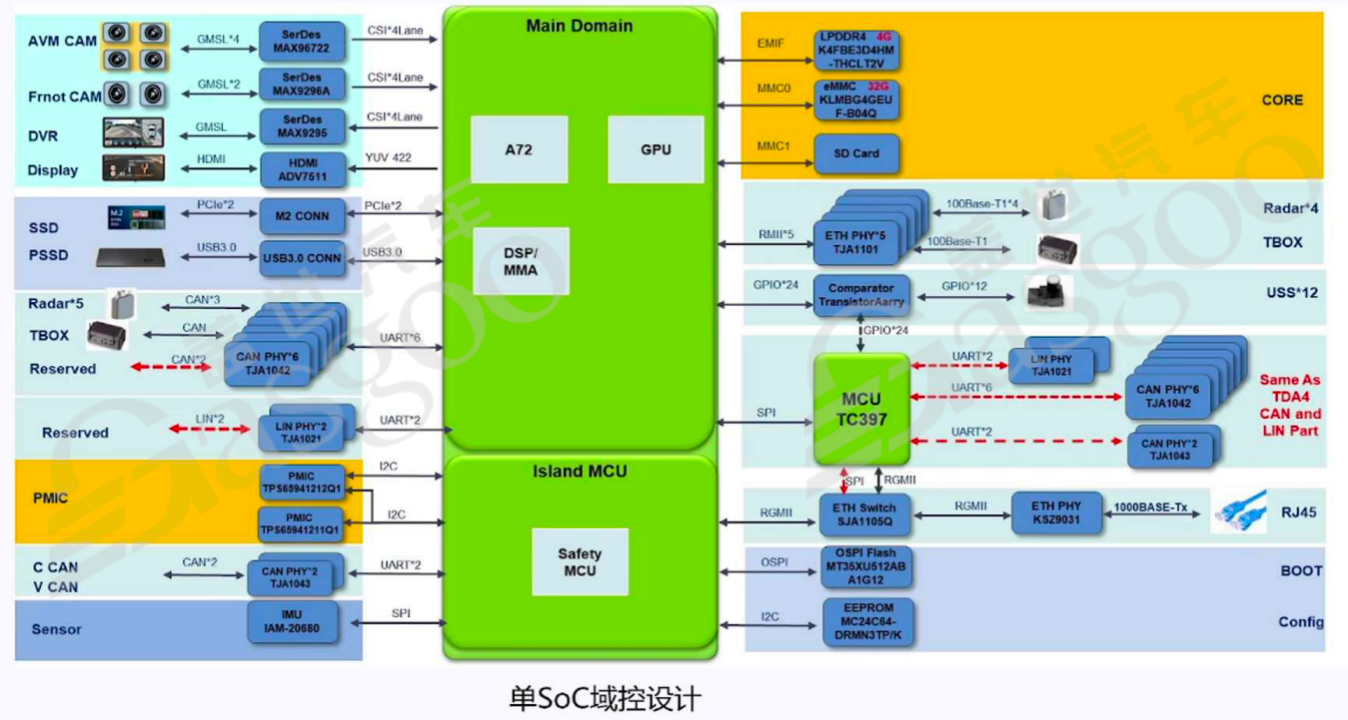
在数据传输方面,外部摄像头通过GMSL接口接入,经过MAX9672解串器后,转换为CSI接口与SOC进行连接,确保图像数据能够高效传输至芯片内部进行处理。雷达数据通过CANFD进入雷达收发器,再经过特定的处理单元(如UU等)进行处理。电源管理芯片负责对系统的电压进行管理,通过硬件设计方式分配不同的电压域,如5伏、3.3伏、12伏等,为各个芯片和模块提供稳定的电源供应。此外,系统还包含多种其他接口和模块,如PCle用于外接硬盘(SSD),实现大容量数据存储;USB3.0用于设备连接和数据传输;SPI、I2C等接口用于芯片间的通信和配置等。整个域控设计涵盖了多种芯片和模块,协同工作以实现车辆的自动驾驶和智能控制功能,一般来说,一个ADAS预控制器中包含30个左右的芯片,其中两个为主芯片,28个为副芯片,共同构建了一个复杂而高效的系统。
*版权声明:本文为盖世汽车原创文章,如欲转载请遵守 转载说明 相关规定。违反转载说明者,盖世汽车将依法追究其法律责任!
本文地址:https://auto.gasgoo.com/news/202502/17I70418634C108.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921



















