

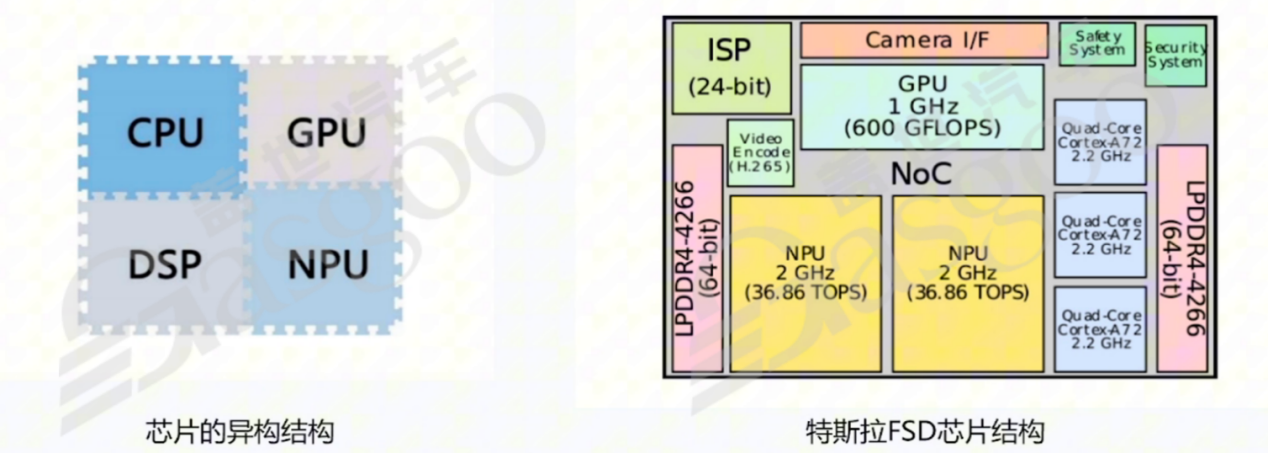
SoC,即片上系统,英文全称为system on chip,是将多种不同类型的芯片集成在一块芯片上的技术。这些集成的芯片包括中央处理器(CPU,central processing unit)、图形处理器(GPU,graphic process ingunit)、现场可编程门阵列(FPGA,Field-Programmable Gate Array)、专用集成电路(ASIC,Application-Specific Integrated Circuit)、神经网络处理器(NPU,Neural Network Processing Unit)、存储器以及蓝牙芯片等。以高通的8155芯片为例,它是一款常用于座舱的SoC型号。8155集成了CPU、GPU、AI引擎(算力约20 TOPS)、摄像头图像信号处理器(ISP),还具备集成音频处理功能,并且集成了Wi-Fi和蓝牙技术。再看特斯拉的FSD芯片,其集成了CPU、GPU、NPU、硬件编解码模块、ISP和内存等组件。在实际研发工作中,常接触到SoC和微控制单元(MCU,Micro controller Unit)这两个概念,然而从百科定义上看,二者存在一定相似性,容易混淆。实际上,二者在算力、构成等方面存在显著差异。
从算力角度来看,SoC通常具有强大的算力,例如其AI算力可达数十甚至上百TOPS,CPU算力可达几百KDMIPS,能够承担复杂运算和高强度处理任务。而MCU虽然也配备CPU,但其算力相对微弱,与SoC不在同一数量级。在构成方面,二者的存储器规模差异巨大。SoC的内存容量通常以GB为单位,甚至还可外接大容量存储设备,如UFS,容量可达128GB或512GB。相比之下,MCU的存储器则以KB或MB为单位,常见的是配置64MB左右的pflash和dflash。此外,MCU是高度集成的微型系统,内部集成了时钟、ADC、电源处理单元、系统时钟(如STM,system time module)等组件,还拥有众多外设接口以及内部通信总线。给MCU接上电源,在完成基本的板子设计和贴片等操作后,它便能够运行。而SoC则需要外接辅助设备,例如若要将Linux操作系统、虚拟机、板级支持包(BSP)等烧录进SoC,必须外接硬盘(如EMMC等存储设备),否则无法完成加载。这是因为SoC的设计重点在于运算集成化,为降低成本、提高通用性,会将与运算性能无关的部分,如大容量存储和电源模块等置于芯片外部,由客户根据需求自行选型配置。由此可见,MCU是专门用于特定控制场景的芯片,因其功能专一,所以能够将存储和时钟等集成在内部。而SoC功能多元化,应用场景广泛,为适配不同场景,会尽量排除受场景影响较大的部分。除了上述差异,二者在其他方面还有一些细微差别,但这两个概念的核心区别主要体现在这些方面。接下来介绍几种常见的芯片类型。CPU作为中央处理器,主要负责逻辑运算。其主频较高,能够运行如Linux、QNX等大型操作系统(在满足功能安全要求的情况下)。CPU具备强大的进程调度能力,可支持多进程以及成百上千个线程的复杂调度。但需要注意的是,对于“支持多进程或成百上千个进程的复杂调度”这一表述并不准确,以常见的ARM的Cortex-A78核为例,假设其为12核,若一个核运算一个进程,那么最多同时运行12个进程;若一个进程绑定两个核,则最多运行6个进程。不过在多线程方面,CPU可以通过分时调度实现高并发,即同一进程下的多个线程可以并发执行。CPU的应用场景广泛,常用于传感器数据的输入、预处理(如二维图像到三维空间的变换、四维数据到三维数据的转换等复杂计算)、加速器的调度(涉及大量进程和线程的调度)、感知融合(例如图像数据和雷达数据的决策运算,需进行复杂的条件判断和数据处理)以及导航规划等软件模块的部署。在激光雷达数据处理中,CPU承担着主要的算力消耗。
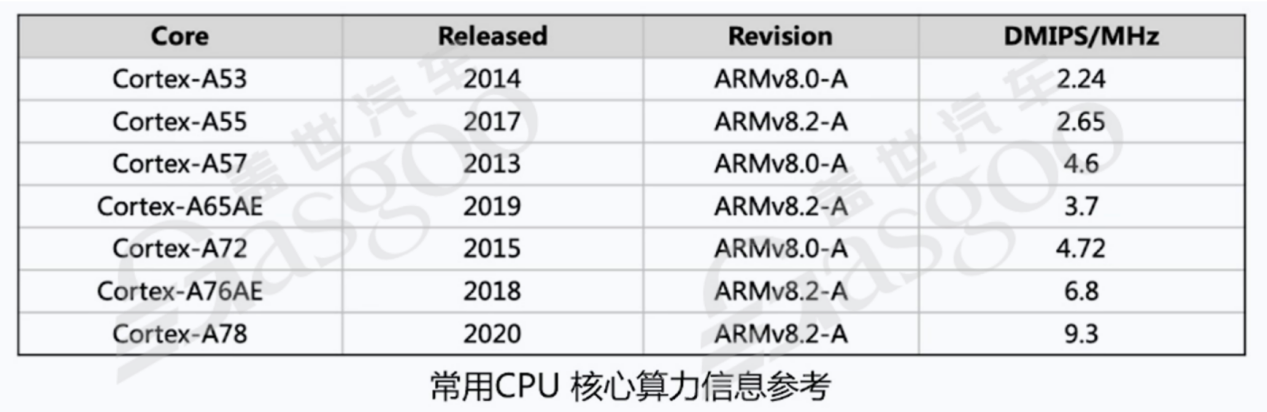
衡量CPU算力的常用单位是KDMIPS(具体含义为每秒钟执行百万次指令的千倍,即10的9次方次特定复杂指令运算,实际运算中代表10的12次方,也就是百亿次特定复杂指令运算)。这一特定算法模拟了CPU正常运行时的基本场景,包含各种计算机访问、调度和切换指令。例如,英伟达OrinX的CPU采用12核A78架构,在主频2GHz下,算力可达220 KDMIPS,意味着该CPU每秒能够运算220乘以100亿次特定指令。数字信号处理器(DSP,Digital Signal Processing)是一种具有特殊结构的微处理器,与通用微处理器(CPU)有所不同。以图像信号处理器(ISP,Image Signal Processing,它是一种特殊的DSP)为例,在摄像头传感器工作时,外部感光单元接收到的光信号会转换为电频信号,不同强度的光会产生不同强度的电信号,这属于模拟电路范畴。DSP的首要任务是将模拟电路信号转换为数字电路信号。例如,对于800万像素的摄像头,其原电子感光元件会产生800万个介于0伏到0.5伏的电压信号,这些电压信号代表不同的像素信息。DSP需要将这些模拟信号转换为数字信号,如将接近0.5伏的红色像素信号转换为255(近似值),0伏转换为0,0.3伏转换为约100多(如178)等,从而将连续的线性电压信号转换为0101的数字信号。
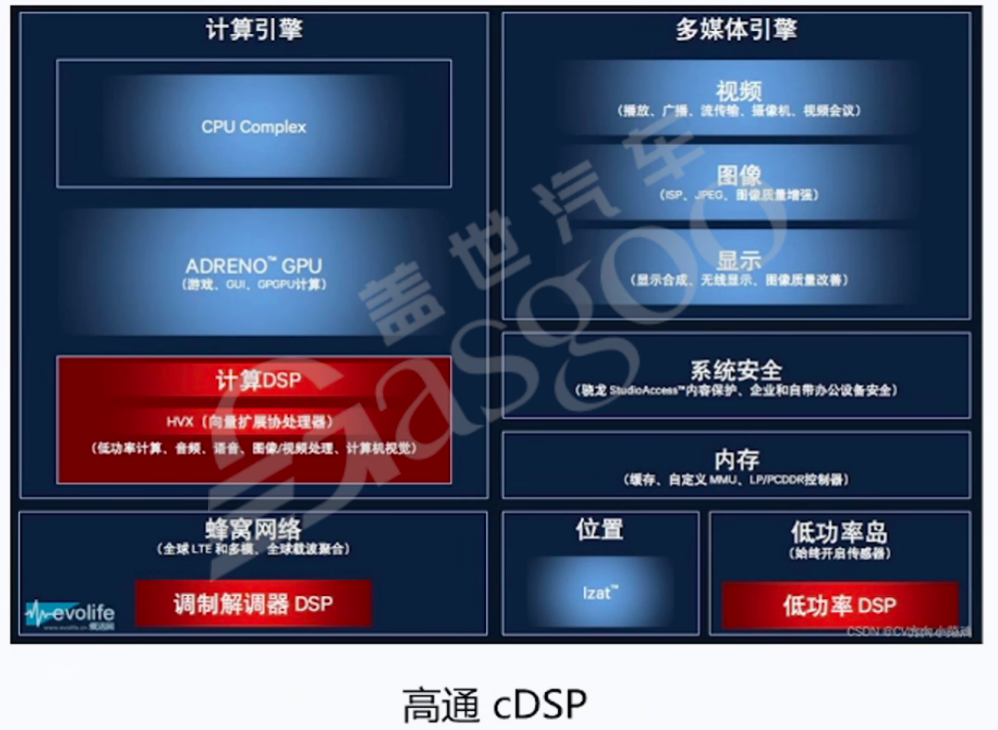
然而,DSP的工作不仅仅是模数转换,更重要的是对数字图像数据进行处理。当图像数据进入DSP后,会进行大量复杂的运算。以800万像素、帧率为30帧/秒的图像为例,每秒进入的数据量为8000万乘以30倍(假设每个像素用10比特表示,若用12比特表示数据量更大),若处理五分钟的图像数据,运算量将达到惊人的数量级。若使用CPU处理如此庞大的数据量,会严重消耗CPU算力,导致其无法正常运行其他进程和操作系统。因此,需要专门的DSP来处理这类数据。与CPU不同,DSP采用并行处理方式,能够同时处理大量相同类型的数据。在图像信号处理方面,DSP负责白平衡调整、3A(自动曝光、自动对焦、自动白平衡)处理、去畸变、拜尔阵列(如RGB或YUV颜色空间转换)处理以及降噪等多种操作。可以说,DSP是专门用于处理信号的单元,它无法像CPU一样运行操作系统。MCU在CPU的基础上,增加了随机存取存储器(RAM)、只读存储器(ROM)、计数器/定时器以及输入输出(I/O)接口等组件,集成构成了一个小而完善的微型计算机系统,被称为“芯片级别的芯片”,是传统汽车中最常用的芯片类型。以TI的TDA4VM芯片内置的MCU为例,它控制着汽车内众多电子系统,包括多媒体、音响、导航、主动悬挂等。作为汽车电子控制系统的核心,MCU具备耐高温、耐振动等车规电子器件的特性。
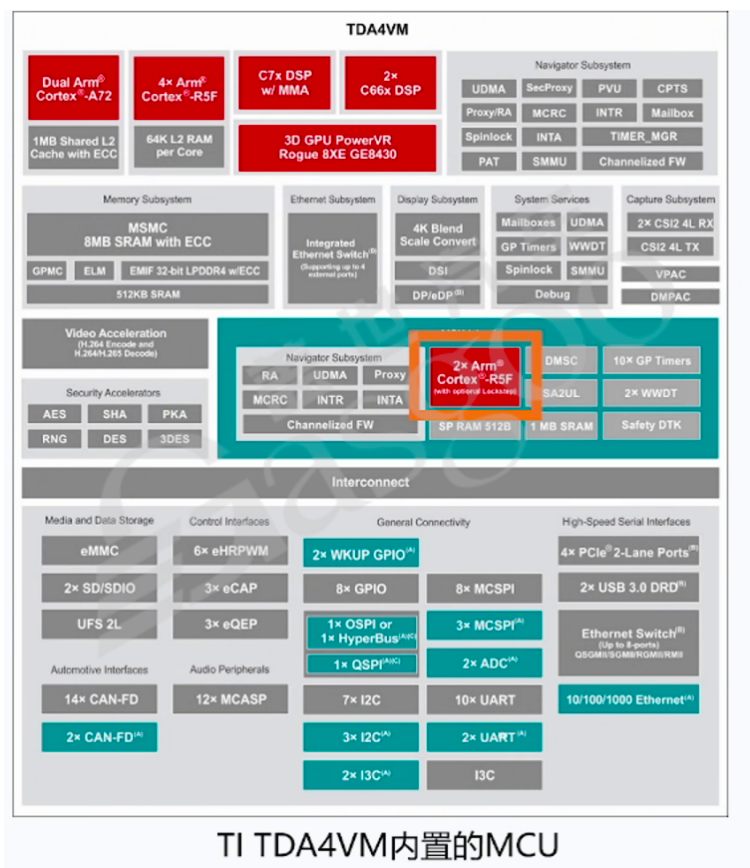
与CPU相比,MCU性能相对较弱,但在实时性和安全性方面表现更为出色,其功能安全等级可达ASILD级别。因此,MCU一般用于运行整车的数据交互、诊断、控制算法等软件。
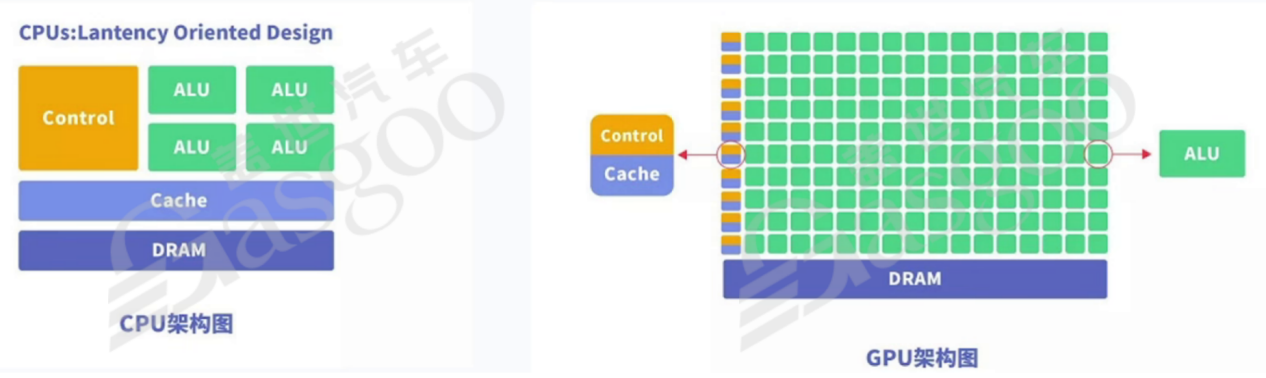
GPU,即图形处理器,是一种特殊形式的处理器,也具备并行处理能力,但与DSP的应用场景有所区别。以3D游戏中的人物图像变化为例,在人物的正脸、侧脸转换过程中,涉及到眼睛、嘴巴等部位的坐标、纹理和颜色等信息的空间位置转换,以及像素的3D坐标变换。英伟达的GPU通常具有大量核心,例如2048个核,相比之下,CPU的Cortex-A78核一般为12个。GPU可以利用多个核心并行处理像素信息,一个核处理一个像素,大大提高处理效率。在处理图像时,GPU需要进行大量的浮点运算。因为在3D图像的像素变换过程中,无法保证像素的跳变都是整数变化,例如人物脸部移动时,鼻子和眼睛的移动距离可能存在小数,这就需要GPU进行浮点运算以保证图像的细腻度和真实感。因此,GPU常以浮点运算作为其运算单位,运算能力一般也以百亿次为数量级衡量。FPGA,即现场可编程门阵列,具有独特的特性。与CPU不同,CPU从工厂生产出来后其架构和功能便固定下来,难以修改。而FPGA允许用户根据自身需求进行重复编程。其基本原理是在芯片内集成大量的数字电路基本门电路以及存储器,用户通过烧入FPGA配置文件来定义这些门电路以及存储器之间的连线。这种烧录操作并非一次性的,可以重复编写定义和配置。
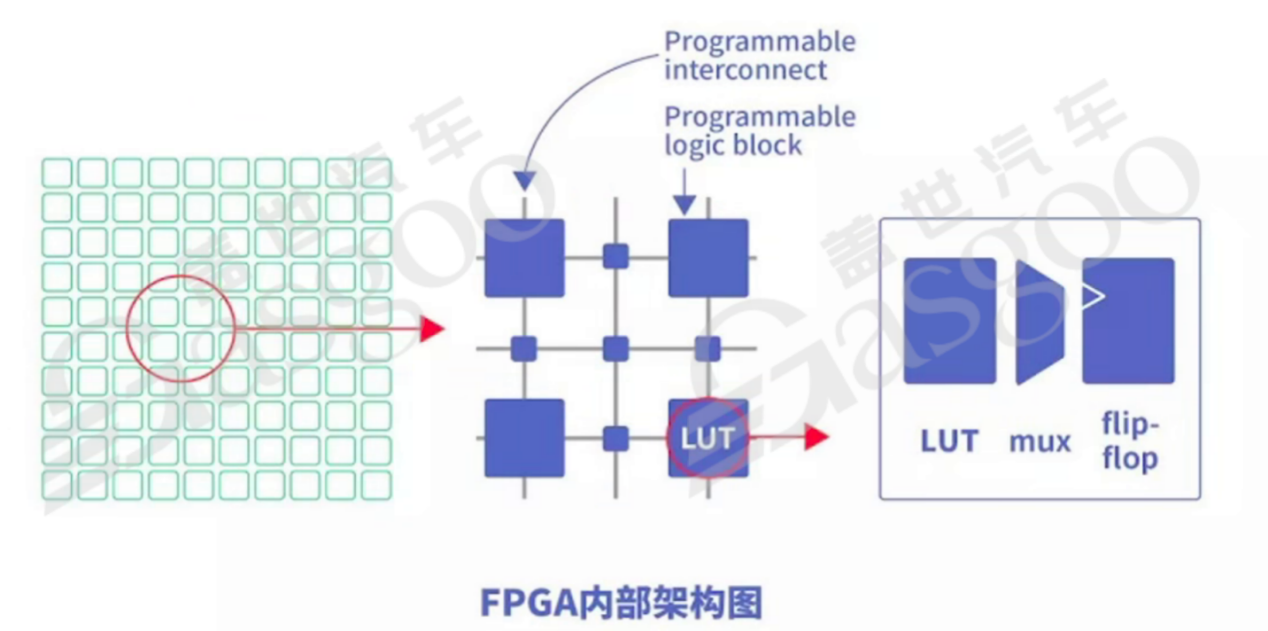
FPGA的优点众多,它可以无限次编程,具有较低的延时性,同时具备流水线并行和数据并行能力(GPU仅具备数据并行),实时性强且灵活性高。例如,用户可以使用同一套FPGA,通过编程将其设计成CPU、GPU或DSP等不同功能的芯片,适用于不同的项目需求,能够快速迭代。然而,FPGA也存在一些缺点,其开发难度较大,价格相对昂贵。并且随着产量的增加,FPGA的成本优势逐渐丧失,这也是AMD在推广FPGA时面临的挑战之一。NPU,即神经网络处理器,是针对特定算法进行加速设计的芯片,属于专用定制芯片(ASIC的一种)。NPU在电路层模拟神经元,通过突触权重实现存储和计算一体化,能够使用一条指令完成一组神经元的处理,大大提高了运行效率,广泛应用于大数据处理、图像处理等领域。尤其在高性能、低功耗的移动端,NPU在功耗、可靠性、体积方面具有显著优势。
以特斯拉FSD中的NPU为例,其采用MAC阵列(乘积累加运算,Multiply Accumulate)作为神经网络加速的核心。卷积运算、点积运算等复杂的神经网络运算都可以分解为多个MAC指令,从而提升运算效率。NPU普遍以OPS(Operations Per Second,每秒操作次数)为单位来评估算力,1TOPS代表每秒可进行一万亿次操作。其算力的计算公式为TOPS=MAC矩阵行×MAC矩阵列×2×主频(其中1个MAC为1次乘法和1次加法,共2次运算操作)。例如,特斯拉FSD中的NPU主频为2GHz,每个NPU的算力为36.86TOPS,该芯片采用2个单核NPU,其峰值算力可达73.7TOPS(INT8)。

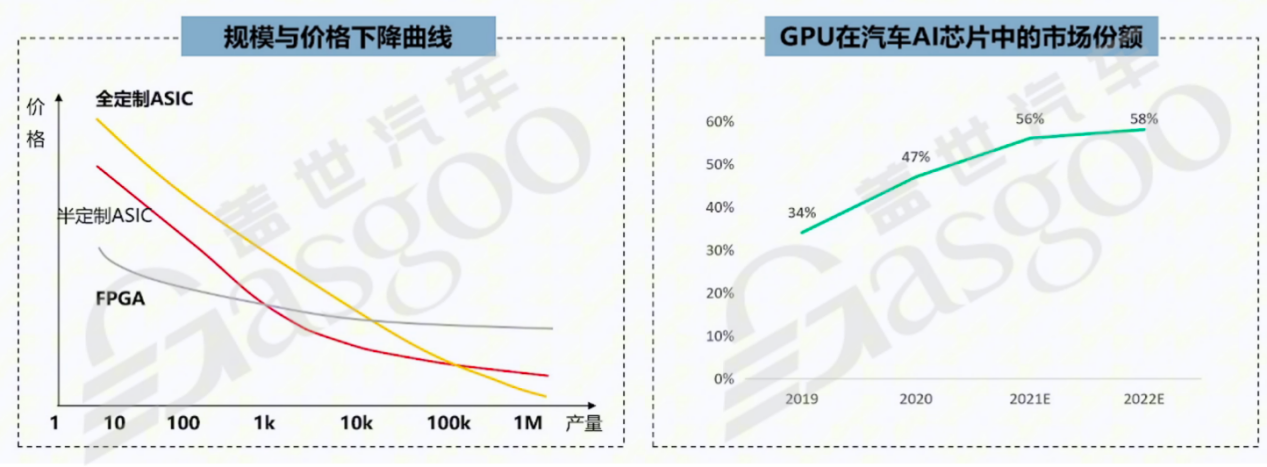
NPU是专门为神经网络设计的处理器,主要进行加法和乘法的整形运算。它与其他芯片功能差异明显,无法像CPU、GPU、DSP或MCU那样执行多种复杂任务,只能专注于神经网络中的加法和乘法运算。但正是这种专注性,使得相关企业在设计芯片时能够简化设计流程,降低研发成本,推动了如地平线、特斯拉等企业在该领域的发展。不同类型的芯片在性能指标、开发速度、成本以及适用场景等方面存在差异。在性能指标方面,CPU的算力使用KDMIPS衡量,用于处理复杂运算;GPU由于主要处理图像处理,涉及大量浮点运算,衡量单位较为复杂;FPGA因其可灵活配置成不同功能芯片,需根据配置后的功能选择相应衡量单位,如配置成CPU用KDMIPS衡量,配置成GPU用GFLOPS衡量,配置成类似NPU功能时可用TOPS衡量;ASIC(当作为NPU时)使用TOPS衡量算力。在开发速度上,CPU和GPU开发速度较快,这是因为市场上存在大量现成的IP可供选择,如高通、ARM的CPUIP,英伟达的GPUIP等。FPGA的开发也相对较快,其灵活性使得开发过程可以快速调整。而ASIC和NPU的开发速度较慢,原因是目前市场上缺乏现成的IP,企业只能依赖如地平线等专业厂商的研发成果,在其产品推出后才能进行相关应用开发。成本方面,由于ASIC和NPU开发时缺乏现成IP,需要企业投入更多研发成本,因此成本相对较高。FPGA虽然单价成本较高,但因其可重复编程、灵活性强,试错成本较低,并且在大规模生产时成本能够有所降低。适用场景上,CPU应用广泛,几乎涵盖所有领域;GPU主要用于图像处理,特别是3D图形处理;FPGA除了在常规的计算领域应用外,还适用于科研等对灵活性要求较高的场景;NPU的应用场景则较为单一,主要集中在消费类电子和汽车等特定领域的神经网络相关计算任务。
*版权声明:本文为盖世汽车原创文章,如欲转载请遵守 转载说明 相关规定。违反转载说明者,盖世汽车将依法追究其法律责任!
本文地址:https://auto.gasgoo.com/news/202502/17I70418632C108.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921


















