
盖世汽车讯 安全高效地控制车辆是自主系统面临的一项重大挑战,研究人员正日益探索强化学习作为一种潜在的解决方案。
据外媒报道,来自泰国国立法政大学(Thammasat University)的Nutkritta Kraipatthanapong、Natthaphat Thathong和Pannita Suksawas及其同事,展示了一种将强化学习与成熟的稳定性分析原理相结合的新方法。他们的研究引入了一个基于李雅普诺夫的强化学习框架(Lyapunov-based reinforcement learning framework),该框架将策略优化与李雅普诺夫稳定性约束相结合,确保车辆即使在动态环境中也能保持安全可预测的行为。这项研究是开发可证明安全的自主车辆控制系统的关键一步,并为将经典控制理论与现代机器学习技术相结合开辟了新的途径。
图片来源:arXiv预印本服务器
可复现性、稳定性与强化学习集成
该研究论文全面探讨了如何将强化学习与李雅普诺夫稳定性分析相结合,为未来的研究奠定了坚实的基础。该研究深入剖析了理论框架,并提供了详细的实践实现,体现了对严谨研究和可复现性的承诺,提供了所有必要的代码、配置和训练权重。论文对结果进行了详细分析,讨论了其优势和局限性,并附有包含补充信息的详尽附录。为了进一步完善这项工作,研究人员可以扩展对变分量子电路优势的阐述,解释其为何在该特定问题上优于经典神经网络,并与基线深度强化学习(DRL)算法进行更详细的比较,包括具体的超参数。
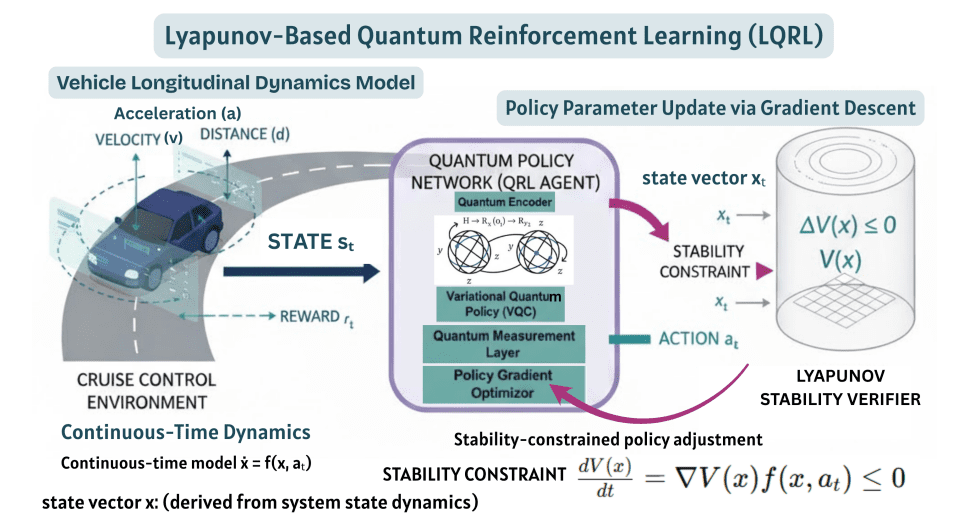
基于李雅普诺夫量子强化学习的安全控制
该新型基于李雅普诺夫的量子强化学习(LQRL)框架旨在实现自动驾驶车辆的安全稳定控制,尤其针对纵向巡航控制场景。这项工作率先将李雅普诺夫稳定性分析直接集成到量子策略梯度学习过程中,确保了渐近安全性和收敛性,这是对现有强化学习方法的一项重大改进。该系统采用连续时间自适应巡航控制模型,模拟车辆状态,包括间距误差、相对速度和自身速度,所有这些状态都在动态变化的环境中演变。为了精确地模拟车辆动力学,研究人员构建了一个由微分方程描述的连续时间系统,该系统描述了间距、相对速度和自身速度的变化,并以时间步长为0的欧拉积分环境实现。
LQRL框架的核心在于一个二次李雅普诺夫候选函数(quadratic Lyapunov candidate function),该函数由平方间距误差、相对速度和自身速度组合而成,并以正系数加权,用于评估系统稳定性。研究人员随后推导出该李雅普诺夫函数的时间导数,并建立了一个稳定性条件,要求其变化率小于或等于一个负常数,从而确保系统收敛到稳定的平衡状态。为了在训练过程中强制执行此稳定性条件,研究团队引入了一个李雅普诺夫惩罚项,有效地惩罚违反稳定性约束的轨迹。
强化学习奖励函数经过精心设计,旨在平衡多个目标,包括最小化间距误差、加速度幅值和加加速度,从而兼顾安全性和乘客舒适度。策略网络是一个双层变分量子电路代理,它利用参数化的单量子比特旋转门将车辆状态映射到控制动作,从而能够高效地探索控制空间并促进学习过程。这种将李雅普诺夫稳定性分析与量子启发式强化学习相结合的创新方法,代表着在自主系统和混合量子-经典优化领域实现可证明安全控制的重要一步。
李雅普诺夫稳定性保障量子车辆控制
科学家们开发了一种新型的基于李雅普诺夫的量子强化学习(LQRL)框架,该框架将策略优化与李雅普诺夫稳定性分析相结合,用于连续时间车辆控制,为量子安全强化学习树立了新的标杆。这项工作成功地将李雅普诺夫稳定性验证嵌入到量子策略学习中,从而在动态环境中实现可解释且具有稳定性感知的控制性能。这一突破将李雅普诺夫控制理论与量子强化学习联系起来,为连续时间学习系统提供了严格的稳定性保证。LQRL框架将量子策略梯度约束在李雅普诺夫递减区域内,确保系统渐近收敛到平衡态,同时在随机量子扰动下保持安全运行。
利用纵向车辆巡航控制场景进行的实验验证了该框架的性能,证实了其在实际应用中的潜力。通过将李雅普诺夫函数嵌入量子策略奖励中,控制器确保了安全的跟车距离、有界加速度和节能的驾驶模式。结果表明,LQRL框架实现了渐近收敛和安全性,为在自主系统中实现可证明安全的量子控制奠定了基础。所推导出的理论公式为量子学习环境中的稳定性保证提供了严谨的基础,而自适应巡航控制中的实现则为实际物理系统中的量子安全强化学习树立了新的标杆。这项研究将李雅普诺夫稳定性理论与量子策略梯度优化相结合,取得了显著进展,为在连续控制任务中实现数学上可证明的安全性保证提供了一条途径。
李雅普诺夫稳定性指导量子强化学习
本研究提出了一种基于李雅普诺夫的新型量子强化学习(LQRL)框架,成功地将量子策略优化与稳定性约束控制理论相结合。通过将李雅普诺夫递减条件嵌入量子策略梯度,该团队实现了基于学习的连续时间系统控制,该控制由理论稳定性原理指导。基于自适应巡航控制场景的仿真实验验证了该方法的可行性,展示了其平稳的控制性能以及与李雅普诺夫稳定性准则的部分一致性。尽管由于正则化强度的限制而观察到一些瞬态不稳定性,但LQRL代理仍保持了有界控制动作并表现出总体稳定性趋势。
分析证实了适中的控制强度和有限的李雅普诺夫能量,凸显了混合量子李雅普诺夫设计对能量感知学习的贡献。尽管存在这种瞬态行为,但结果表明,将李雅普诺夫稳定性集成到量子增强策略网络中具有可复现的基础。未来的工作将集中于自适应正则化技术、在近期量子设备上的硬件实现,以及将该框架扩展到多智能体系统,从而为可扩展的量子安全控制解决方案铺平道路。

*特别声明:本文为技术类文章,禁止转载或大篇幅摘录!违规转载,法律必究。
本文地址:https://auto.gasgoo.com/news/202510/30I70436093C409.shtml
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921
















