
盖世汽车讯 据外媒报道,日本东京科学大学(Institute of Science Tokyo)的研究人员开发出可扩展且高效的图神经网络加速器BingoCGN,能够通过图分区实现实时大规模图推理。这一突破性框架采用创新的跨分区消息量化技术和新颖的训练算法,显著降低了内存需求,并提高了计算效率和能效。
图片来源: 东京科技大学
图神经网络(GNN)是强大的人工智能(AI)模型,旨在分析复杂的非结构化图数据。在这类数据中,实体表示为节点,实体之间的关系表示为边。GNN已成功应用于许多实际应用,包括社交网络、药物研发、自动驾驶和推荐系统。尽管GNN潜力巨大,但实现对自动驾驶等任务至关重要的实时大规模GNN推理仍然充满挑战。
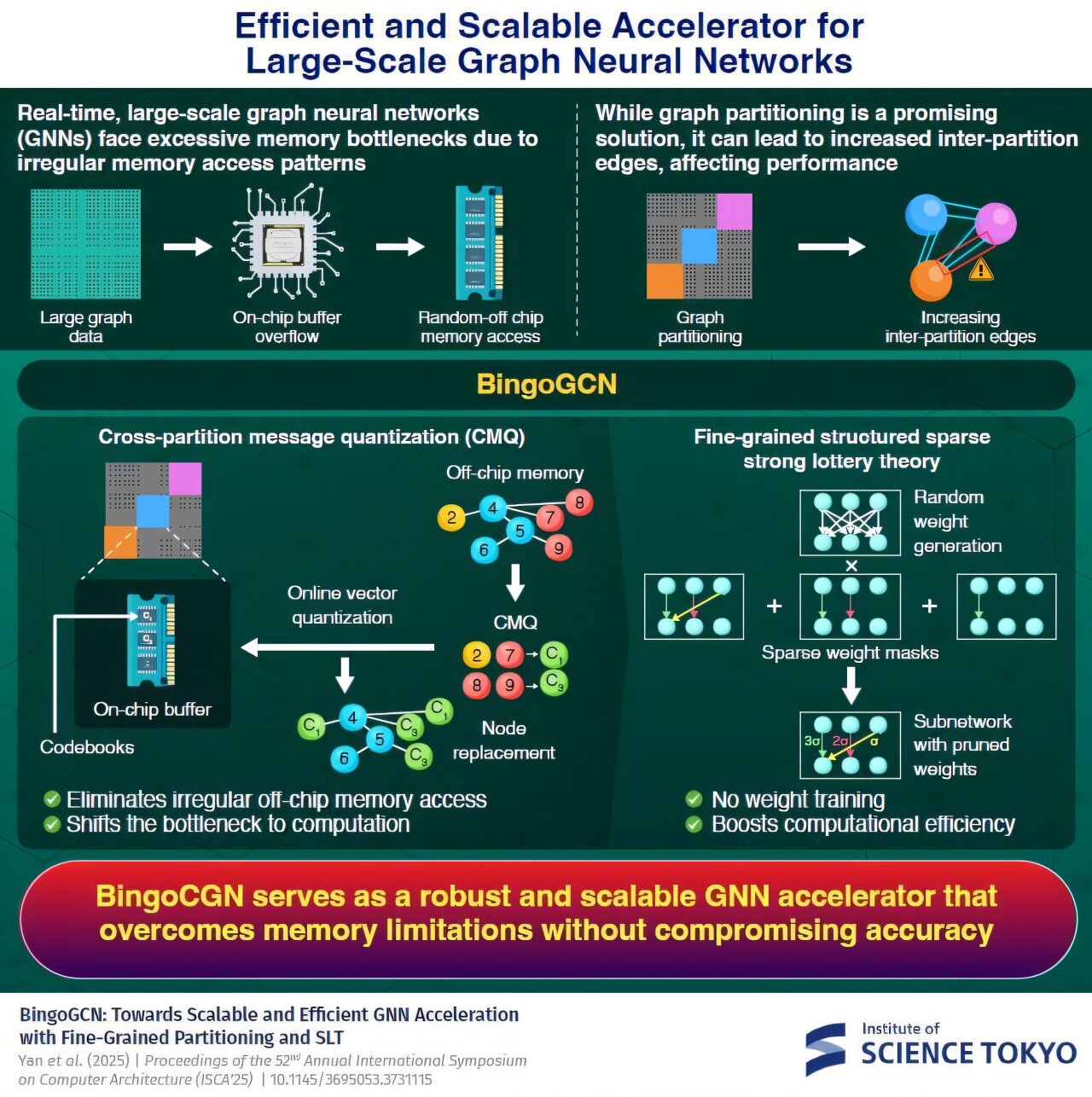
大型图需要大量内存,这通常会溢出片上缓冲区(即集成在芯片中的内存区域)。这迫使系统依赖于速度较慢的片外内存。由于图数据存储不规律,这会导致内存访问模式不规律,从而降低计算效率并增加能耗。
一个有前景的解决方案是图分区,将大型图划分为较小的图,每个图分配各自的片上缓冲区。随着分区数量的增加,这将导致内存访问模式更加本地化,并且缓冲区大小要求也更小。
然而,这种方法并非完全有效。随着分区数量的增加,分区之间以及分区间边缘的链接也随之大幅增长。这需要增加片外内存访问,从而限制了可扩展性。
为了解决这个问题,由日本东京科学大学副教授Daichi Fujiki领导的研究团队开发了一种名为BingoCGN的新型、可扩展且高效的GNN加速器。
Fujiki解释说:“BingoCGN采用了一种名为跨分区消息量化(CMQ)的新技术,该技术可以汇总分区间消息流,消除不规则的片外内存访问,并采用一种可显著提高计算效率的新训练算法。”
CMQ采用一种称为矢量量化的技术,该技术对分区间节点进行聚类,并使用称为质心的点来表示它们。节点根据其距离进行聚类,每个节点被分配到与其最近的质心。对于给定的分区,这些质心会替换分区间节点,从而有效地压缩节点数据。质心存储在称为码本的表中,这些表直接驻留在片上缓冲区中。
因此,CMQ允许分区间通信,而无需不定期且成本高昂的片外内存访问。此外,由于此方法需要频繁地读写内存中的节点和质心,因此该方法采用分层树状结构的码本,包含父质心和子质心,从而在保持准确性的同时降低了计算需求。
虽然CMQ解决了内存瓶颈,但它将负担转移到了计算上。为了解决这个问题,研究人员基于强彩票理论开发了一种新颖的训练算法。在该方法中,GNN使用随机权重进行初始化,这些权重由随机数生成器在芯片上生成。然后,使用掩码修剪不必要的权重,形成一个更小、密度更低或稀疏的子网络,该子网络的精度与完整GNN相当,但计算效率显著提高。此外,该方法还结合了细粒度(FG)结构化修剪,即使用具有不同稀疏度的多个掩码,构建更小、更高效的子网络。
“通过这些技术,BingoCGN即使在精细划分的图数据上也能实现高性能的GNN推理,这在以前被认为是困难的,”Fujiki表示。“我们的硬件实现在七个真实数据集上进行了测试,与最先进的加速器FlowGNN相比,速度提高了65倍,能效提高了107倍。”
这一突破为实时处理大规模图数据打开了大门,为GNN在现实世界中的多样化应用铺平了道路。
*特别声明:本文为技术类文章,禁止转载或大篇幅摘录!违规转载,法律必究。
本文地址:https://auto.gasgoo.com/news/202506/25I70427762C409.shtml
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921













