在自动驾驶技术蓬勃发展的当下,数据闭环成为推动其持续演进的核心驱动力。这一概念贯穿于自动驾驶系统从数据采集、处理、模型训练,到仿真测试、车端部署与反馈优化的全过程,是实现自动驾驶技术从理论迈向实际应用、从初级阶段走向高度智能化的关键所在。
一、自动驾驶安全性与数据量的紧密关联
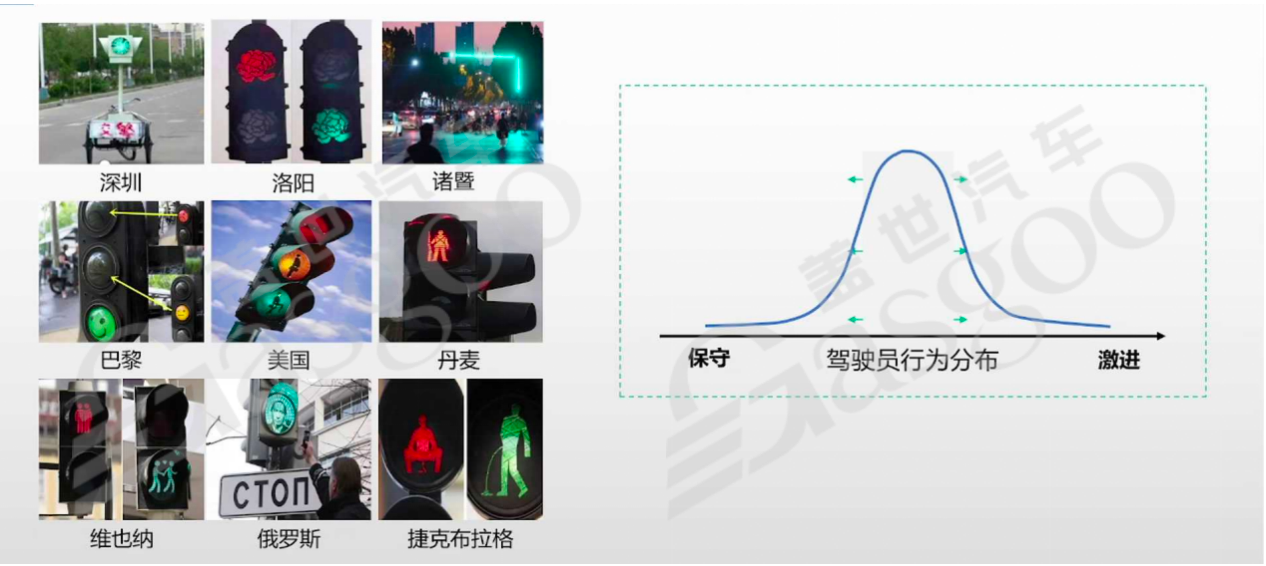
(一)衡量自动驾驶安全性的困境
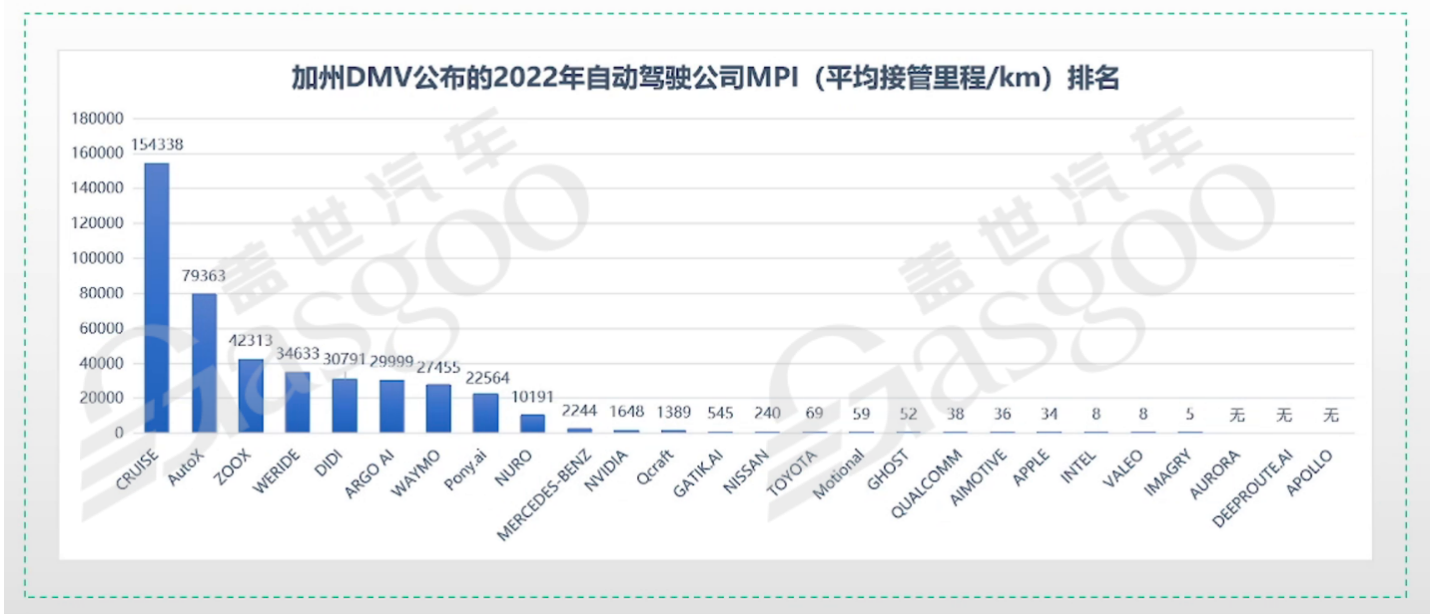
自动驾驶安全性的评估是一个复杂且充满挑战的问题。驾驶员的驾驶风格差异巨大,从保守到激进,使得基于驾驶员行为来确保自动驾驶安全性变得极为困难。以加州DMV公布的2022年自动驾驶公司MPI(平均接管里程/km)排名为例,不同公司的表现参差不齐,如阿波罗未公布数据,而部分公司的平均接管里程数据虽有呈现,但这一指标并不能完全代表后续的实际安全性能。当前单一的评估指标难以全面、准确地衡量自动驾驶的安全性。
(二)数据量对自动驾驶的关键意义
为证明自动驾驶的安全性能,需要车辆行驶极长的里程,如110亿英里。在此过程中,数据量的积累至关重要。一辆车每小时产生的数据量可达1TB,若100辆车每天行驶10小时,产生的数据量则高达1PB。如此庞大的数据量对于自动驾驶技术的发展意义非凡,数据与算法共同构成了自动驾驶系统的核心竞争力。正如吴恩达提出的观点,好的人工智能是80%的数据加20%的算法。丰富、高质量的数据能够支撑算法进行更频繁、更深入的迭代优化,进而提升自动驾驶系统的性能与安全性。
二、数据驱动的自动驾驶技术发展模式
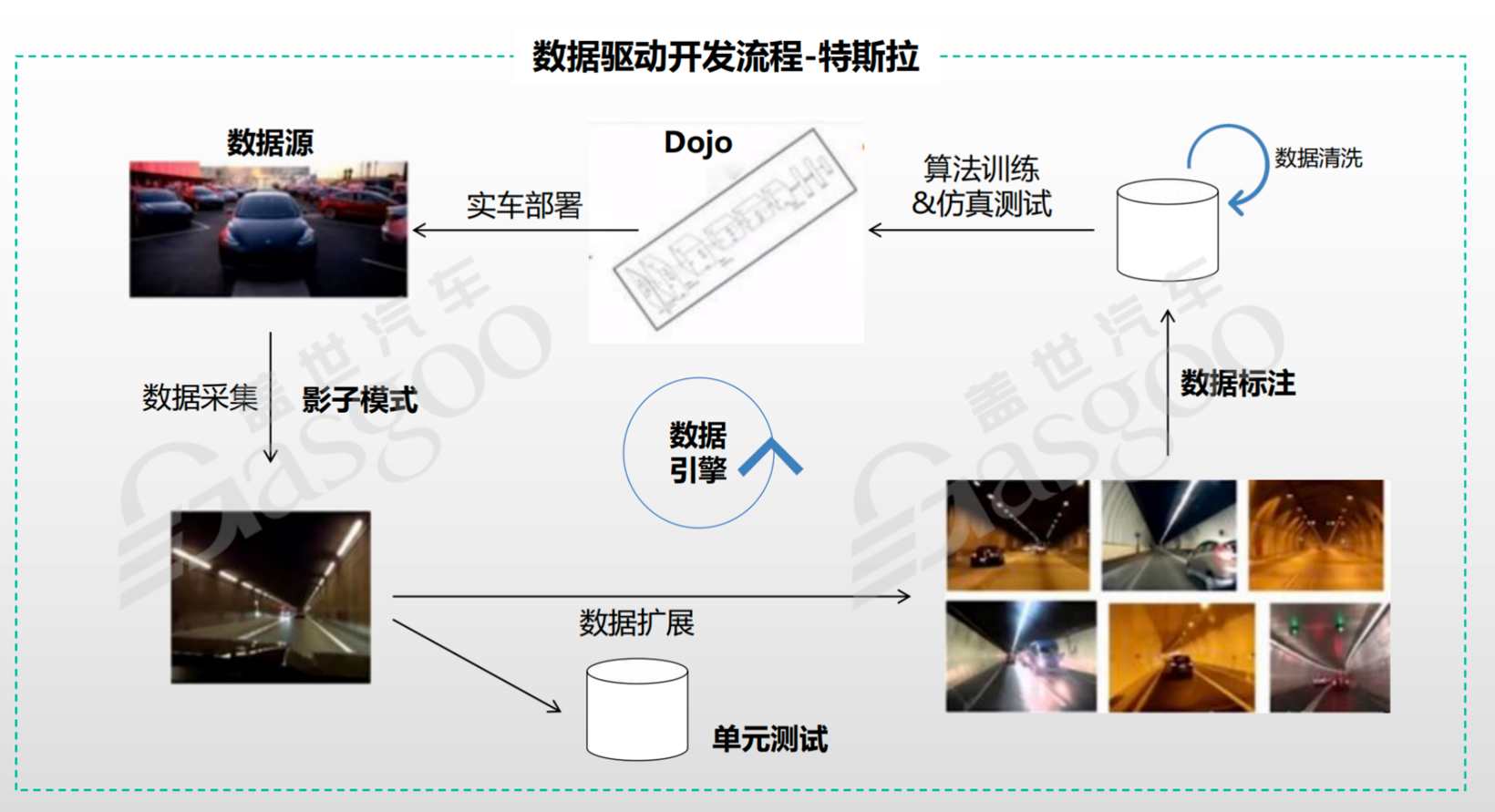
(一)特斯拉的数据闭环实践
数据采集策略:特斯拉采用影子模式,在全球超过150万辆车上部署detector检测器,实时抓取现实中的各类数据。同时,配备一千多人的标准团队对采集到的素材进行处理标注。这种数据采集方式不仅获取了海量的数据,还涵盖了各种复杂的驾驶场景,如雷达视觉不匹配、少见的路面倾斜、急转弯、进出隧道等特殊情况,极大地丰富了数据的多样性。
数据处理与模型训练流程:采集到的数据经数据扩展后,进入数据标注与清洗环节。数据清洗需要去除数据中的噪声,同时根据不同国家的法规要求,擦除地理位置信息、人脸、车牌等敏感信息。数据标注涵盖2D、3D目标物标注、联合标注、车道线标注和语义分割等多种类型,标注过程遵循严格的规范和质检流程,包括标注人员自检、质检员抽检和标注经理抽检,以确保标注数据的准确性和可靠性。完成标注和清洗的数据用于模型训练,特斯拉借助强大的云端服务器进行模型训练,利用公有云弹性算力的优势,不断优化模型性能。
仿真技术的应用:特斯拉运用虚拟仿真技术构建逼真的模拟环境。在这个环境中,不仅视觉效果高度还原现实,车辆和行人的行为、移动方式以及对障碍的反应等细节也与现实世界极为相似。当自动驾驶系统在实际运行中遇到问题时,系统会自动创建仿真场景,用于机器学习训练。此外,特斯拉还通过改变天气、光线、增加复杂的行人和车辆等方式,创造出大量的corner cases(极端情况),进一步丰富训练场景,提升模型应对复杂情况的能力。
(二)其他企业的数据闭环探索
毫末的数据闭环模式:毫末智行构建了一套完整的数据闭环体系,其数据飞轮涵盖数据分析、异构计算、数据标注、数据回流、模型训练、测试验证等多个环节。通过CLA(闭环自动化)工具链,自动筛选出海量黄金数据,驱动算法自动迭代,实现自动驾驶技术的快速发展。在数据采集方面,毫末注重采集车端的各类数据,并将其回传至云端进行处理和分析。在模型训练过程中,充分利用数据闭环的优势,不断优化模型性能,提高自动驾驶系统的准确性和可靠性。
Momenta的数据驱动理念:Momenta强调数据驱动的自动驾驶发展理念,其数据飞轮以海量数据为基础,通过数据标注、算法辅助、安全存储等环节,实现数据的高效处理和利用。在数据采集阶段,Momenta采用多种方式获取数据,包括实际道路测试和仿真模拟等。同时,利用先进的算法对采集到的数据进行筛选和分析,提取有价值的信息,为模型训练提供有力支持。通过数据闭环的不断循环,Momenta的自动驾驶算法能够快速迭代,提升系统的性能和泛化能力。

三、数据采集的关键要点
(一)智能采集的三要素
全:数据采集应尽可能全面,在采集感知数据时,获取规控结果以及相关的EPS、BCM等数据,以便综合判断感知与规控的匹配情况,准确识别算法问题或硬件故障。例如,在车辆转向异常时,通过获取全面的数据,可以判断是转向ECU出现问题,还是算法本身存在缺陷。
小:采集的数据量应保持较小,如特斯拉影子模式下,仅抓取触发前后5-10秒的数据。这样做既能快速上传数据,又能避免对HPC(高性能计算平台)或数据中心资源造成过度占用,确保车辆系统的正常运行。
活:数据采集要具备灵活性,能够根据不同的场景和问题,预置或灵活增加新的采集要求。以特斯拉为例,其设置了多达221个triggers(触发条件),涵盖人机不一致、雷达视觉不匹配、特殊场景、极端天气等多种情况。一旦满足触发条件,系统立即采集数据,确保获取到各种复杂场景下的数据。
(二)数据采集的方式与挑战
车端采集与影子模式:车端采集是获取真实驾驶数据的重要方式,影子模式在其中发挥了关键作用。通过在车辆上部署传感器和数据采集设备,实时采集车辆行驶过程中的各种数据。然而,这种方式面临着数据存储和传输的挑战,如车载硬盘容量有限,大量数据的传输可能导致网络拥堵。此外,数据采集还涉及到用户隐私问题,如何在合法合规的前提下采集数据,是企业需要解决的重要问题。
测试车与硬件在环台架采集:除了车端采集,使用测试车进行专门的数据采集也是常见的方法。测试车可以在特定的场景和条件下进行测试,获取针对性的数据。硬件在环台架采集则通过搭建模拟真实驾驶环境的台架,利用工控机等设备进行24小时不间断测试。这种方式能够在实验室环境中模拟各种复杂场景,提高数据采集的效率和可控性,但搭建和维护硬件在环台架的成本较高。
四、仿真技术在自动驾驶中的应用与挑战
(一)仿真的重要性与作用
补充真实场景数据的不足:尽管通过实际车辆行驶可以获取大量数据,但在自动驾驶技术的发展过程中,仍存在许多难以在现实中遇到的cornercases。仿真技术能够创造出这些极端场景,如动物突然闯入马路、高速上出现异常行人等,为模型训练提供丰富的素材,弥补真实场景数据的不足。
加速模型训练与优化:仿真环境可以快速生成大量的训练场景,大大提高模型训练的效率。通过在仿真环境中对模型进行测试和优化,能够及时发现模型存在的问题,并进行针对性的改进,加速自动驾驶技术的迭代发展。
(二)仿真面临的技术挑战
传感器仿真难题:构建基于场景的多传感器物理模型是仿真的一大挑战。以摄像头为例,要模拟其成像过程,需要精确考虑每个采光元件的光强、电压等参数,这对计算资源和算法的要求极高。对于雷达而言,不仅要进行电磁仿真,还要考虑雷达天线的外壳材料、射频特性以及目标物体对电磁波的反射特性等,实现起来难度极大。
车辆动力学仿真困境:车辆动力学仿真涉及行驶过程中轮胎、空气阻力对车辆的影响,以及驱动与制动、转向之间的相互作用。在高速和极限工况下,建立准确的车辆动力学模型非常困难,因为这些工况下的车辆行为呈现非线性特征。目前,CarSim和CarMaker等车辆动力学模型应用较为广泛,但仍需要不断改进和完善,以满足自动驾驶仿真的需求。

(三)场景库的建设与应用
场景库的来源:场景库是自动驾驶测试的重要资源,其来源主要包括第三方采购、针对场景正向搭建、数据采集发现的corner case反向生成以及对现有场景库进行编辑泛化等。第三方采购的场景库多以标准法规和专家经验数据为主;正向搭建则是根据实际需求主动创建场景;反向生成是基于实际采集到的特殊情况构建场景;编辑泛化是对已有的场景进行修改,如改变天气环境、增加或减少障碍物等,以丰富场景库的内容。
场景库的重要性:场景库相当于自动驾驶测试的“错题本”,是决定自动驾驶算法水平高低的核心竞争力所在。丰富、多样的场景库能够为模型训练提供更全面的场景覆盖,使模型在面对各种复杂情况时能够做出更准确的决策,从而提高自动驾驶系统的安全性和可靠性。
五、数据闭环的优势、成本与发展趋势
(一)数据闭环的显著优势
数据闭环能够有效降低获取长尾数据的成本。通过车端实时采集数据、云端处理与标注、模型训练和仿真测试,再将优化后的新版本通过OTA(空中下载技术)推送到车端,形成一个高效的循环。在这个过程中,利用自动或半自动的数据处理方式,实现算法模型的快速优化,提升模型的泛化能力,使自动驾驶系统能够更好地适应各种复杂的驾驶场景,推动自动驾驶技术的快速迭代发展。
(二)数据闭环的成本构成
数据闭环的初期搭建成本高昂,企业需要自建或租用IDC机房,同时开发或外购工具链软件。后续成本主要包括数据上传流量成本、标注人力成本以及训练、仿真测试所需的服务器成本等。此外,随着数据安全和合规要求的日益严格,企业还需投入大量资源来确保数据的安全存储和合法使用。
(三)数据闭环的发展趋势
目前,特斯拉、小鹏、毫末等众多车企都已建立数据闭环能力。为进一步提升模型训练能力,特斯拉、蔚来、小鹏、毫末、商汤等企业纷纷自建超算中心,以满足日益增长的数据处理和模型训练需求。随着头部企业在数据闭环工具链效率和数据采集体量上的差距逐渐拉大,不同企业之间的算法能力差距也将越来越明显。未来,数据闭环将成为自动驾驶领域竞争的关键因素,推动行业不断向前发展。
在自动驾驶技术的发展进程中,数据闭环无疑是核心所在。它整合了数据采集、处理、模型训练、仿真测试等各个环节,形成了一个相互促进、不断优化的生态系统。尽管目前面临着成本、技术挑战等诸多问题,但随着技术的不断进步和行业的发展,数据闭环将在自动驾驶领域发挥越来越重要的作用,为实现安全、高效、智能的自动驾驶愿景奠定坚实基础。
*版权声明:本文为盖世汽车原创文章,如欲转载请遵守 转载说明 相关规定。违反转载说明者,盖世汽车将依法追究其法律责任!
本文地址:https://auto.gasgoo.com/news/202502/17I70418631C108.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921













