
2024年12月18日,在第二届具身智能产业发展论坛上,清华大学交叉信息研究院博导,清华大学视觉与具身智能实验室主任,千寻智能联合创始人高阳就“具身智能中的数据瓶颈”为主要议题展开分享。
高阳表示,目前AI技术的迅猛发展已经达到了令人惊讶的能力和创新,这个能力的背后便是海量数据的支撑,也就是大语言模型。对于机器人来讲,目前的数据支持还有很大发展空间。我们认为,足够强大的数据支持是具身智能实现高阶发展的关键点。
因此,我们专注数据采集设备的研究以解决数据规划的问题。通过机器人与环境的交互,强化学习的过程,获取信息并反馈给自身,从而不断优化学习过程,进而形成数据飞轮。机器人的学习能力是形成数据飞轮的必要条件,对于具身智能的发展尤为重要。期望十年后,随着老龄化社会的来临,类人机器人能够成为人们日常生活中的重要助手。

高阳 | 清华大学交叉信息研究院博导,千寻智能联合创始人
以下为演讲内容整理:
机器人领域的数据挑战
提及AI,我们首先可能会想到LIM或文生图等模型,这些模型均展现了惊人的能力和创新性。
这些能力背后所依托的,正是海量的数据。例如,大型语言模型已经遍览了互联网上的所有文本;文生图模型,则是通过学习互联网上超过100亿个图像与文本对,经过预训练才达到了如今的性能。然而,在机器人领域,数据却显得尤为稀缺。这并不难理解,因为缺乏有效数据,机器人的研发和应用就难以推进,进而形成了数据匮乏与机器人发展滞后的恶性循环。
下图展示的是机器人领域的一个公开数据集,即便是该领域最大的数据集,也仅包含100万条数据。与文生图模型所使用的100亿级数据量相比,这一数量显然微不足道。

图源:演讲嘉宾素材
正因如此,我们不难发现,当前的机器人往往显得“笨拙”。它们执行任务时颤颤巍巍,这主要是因为数据不足所致。若我们能获取足够的数据,机器人领域的问题或许能迎刃而解。
为了应对这一挑战,学术界近期涌现出许多出色的科研人员和团队,致力于开发各种数据采集设备,以解决数据稀缺的问题。例如,有些团队正在研发类似面试机器人的设备,它们专注于硬件层面的数据采集,而非直接进行人工智能研究。
然而,这些数据采集设备对于我们所需的数据量而言,仍显得力不从心。因为在实际应用中,这些设备的使用效率往往较低,难以满足大规模数据采集的需求。据我估计,为了实现机器人的通用算法能力,我们可能需要数以亿计的数据条目。达到这一数据量所需的投入已远超当前自动驾驶行业的投资规模。
利用互联网数据解决机器人数据瓶颈
那么,我们该如何解决这一数据瓶颈问题呢?今天,我将与大家分享一些学术界的前沿工作,从中我们可以窥见未来解决这一问题的可能途径。接下来,我将介绍我们实验室在数据层面所进行的三项尝试。
首先是我们称之为“Constraints of Parts”的项目,该项目利用空间物件的约束来解决数据瓶颈问题。机器人能够学习如何执行诸如锤钉子、拉抽屉或用木棍按按钮等任务。这一方法的核心思想是,与其从零开始采集数据,不如利用互联网上已有的常识和知识。这些知识和操作指南往往以文本和图像的形式存在于互联网上,我们可以通过解析这些资源,为机器人提供执行任务的指导。
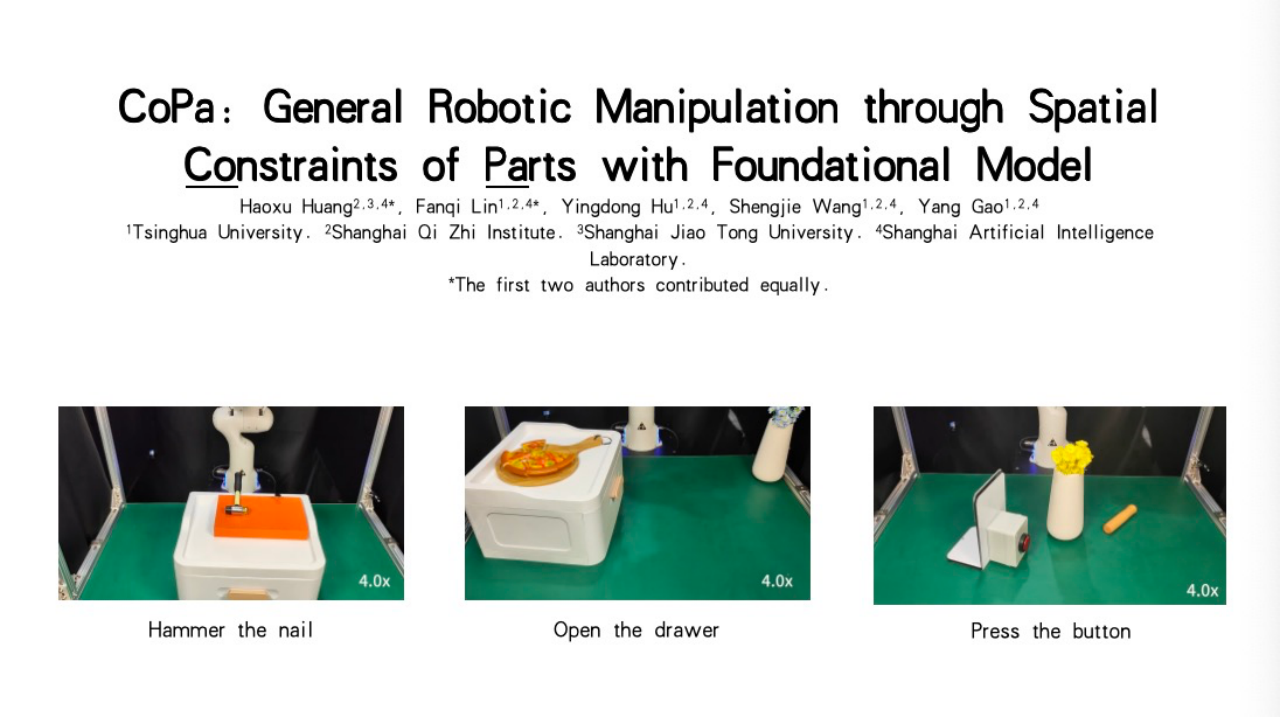
图源:演讲嘉宾素材
为了实现这一目标,我们让大型语言模型按照特定的格式输出指令,这些指令包含了任务执行的具体步骤和空间约束条件。我们发现,当前的视觉语言模型已经具备了一定的这种能力。因此,我们利用这些模型生成数据,并通过数学优化的方法来确定机器人执行任务的最佳姿态和路径。
具体来说,如果我们想让机器人把花放进花瓶里,我们的方法会首先识别出场景中的关键物件——花和花瓶。然后,根据花的形态和花瓶的位置,生成一个抓取姿态,并确保花的主干部分能够垂直插入花瓶口。这一过程涉及到了空间部件的约束和数学优化方法的应用。通过这样的方法,我们可以让机器人自主地完成各种任务,并通过高层规划算法的支持,实现更加复杂和灵活的操作。
这实际上引出了我想分享的第一种思想:利用我们已经积累的海量互联网数据,通过与战略模型交互,为机器人生成大量类似的数据。当前的大型视觉语言模型主要依赖互联网上的文本和图像数据进行训练。
然而,它们对视频数据的利用仍然有限,因为在美国,对视频的理解能力还相对较弱。目前,视频处理的方法通常是将视频拆分成一系列图像,再通过这些图像来微调图像和文本的模型,以达到视频处理的效果。但对于机器人而言,它们更关注的是人类动作的过程,而非静态的场景。
那么,互联网上哪种数据最能描述动态过程呢?这就是我接下来想分享的点:我们能否通过让机器人观看人类做事的视频,来学习人类的动作模式?这样,我们就可以用更少的数据来训练机器人,使其达到同样的目标。这就引出了一个问题:我们如何将互联网上大量的人类或机器动作视频迁移到机器人的基线模型上?
虽然这个想法听起来很直接,但具体实施起来却并不容易。我们需要考虑如何抽取视频中的动作,并将其转化为机器人可以理解和执行的形式。一个可能的解决方案是,让模型去抽取空间上3D点的移动,以此来代表物体的运动行为。例如,我们可以在杯子上撒一些点,然后观察这些点如何随着人类的操控而移动。如果我们能够在任何场景下预测每个物体被人类操控的运动轨迹,那么我们就可以将这种知识传授给机器人。
这种方法的好处是显而易见的,比如它可以处理海量的数据,表示任何形态的运动等。通过这种方式,我们仅使用人类的视频进行预训练,就可以让机器人完成许多复杂的行为,如叠衣服、打开或合上笔记本电脑等。
强化学习与数据闭环提升机器人可靠性
当我们拥有了一个能够执行多种任务的机器人,并且已经通过互联网数据进行了预训练后,我们仍然会面临一个挑战:机器人的可靠性问题。就像自动驾驶汽车一样,即使机器人系统在大部分时间内都表现得很好,但总会有那么一些时刻需要人类的干预。如果将这种干预的成本考虑在内,那么在某些情况下,使用机器人系统可能还不如不使用。
因此,我认为在未来五年内,智能行业将面临一个落地的问题:如何将机器人系统的可靠性提高到极高的水平?我认为,一个有效的方法是形成数据的闭环。就像特斯拉一样,让所有的机器人用户在使用过程中为系统提供数据,从而不断提升机器人的性能和可靠性。
对于机器人而言,我们同样在探索是否能采用类似的方法,使机器人也能够实现数据闭环。然而,这是极难控制的,原因在于其涉及的环节繁多,人类的手部动作极为灵活,且需完成的任务种类庞杂,因此,构建一个能够模拟人类操作的人工系统显得尤为困难。
尽管如此,我们观察到人类在学习新任务的过程中,通过不断练习能够逐步精进自己的技能。以拧螺丝为例,初学者可能需要较长时间才能完成,但随着熟练度的提升,最终可能只需一秒钟就能轻松完成。这一过程,实质上就是强化学习的过程,即个体通过与环境的交互,逐渐熟悉并掌握任务,从而提升任务完成的质量。
通过强化学习,我们在实际工作中取得了显著成效,实现了高达99.9999%甚至更高的成功率。这一成就得益于机器人在现实世界中采集数据,并反馈至模型,使其操作愈发精准。
在一项实验中,我们尝试让机器人完成用水壶浇花的任务。起初,机器人的表现并不理想,甚至无法准确抓住水壶。然而,通过我们提出的物理世界查询算法,让机器人在实际环境中练习,并根据大模型的反馈了解成功与失败的原因,经过短短十分钟的训练,机器人就能夹起水壶,虽然尚不稳定。随着训练时间的延长,至20分钟时,机器人已能较为稳定地夹起水壶,但仍无法完成浇花的动作。最终,在训练一个小时后,机器人不仅能稳固地夹起水壶,还能顺利完成浇花动作。这一过程完全依赖于机器人在环境中的自主交互与学习。

图源:演讲嘉宾素材
这种学习能力对于机器人而言至关重要,是形成数据飞轮的必要条件。我们已在多个任务上进行了类似的强化学习实验,如操控遥控车、打高尔夫球等。结果显示,对于大多数任务,机器人在现实世界中学习一个小时后,其性能就能从20%提升至85%左右,这一提升幅度巨大,且所需时间极短。
目前,我正在创办一家专注于先进智能的公司——千寻智能,致力于研发具身机器人的大脑和智能机器人的本体。我们的愿景是,在未来十年内,让世界上10%的人能够拥有自己的类人机器人。尽管这一目标充满挑战,但我们坚信,无论对于全球文化还是各种生产活动,这都将带来深远的影响。面对恶劣、危险的环境,我们更需努力推进这一目标的实现。
此外,我们的端到端神经网络模型能够自主适应不同位置、不同状态的物体,如自动调整杯子的放置位置,并流畅地完成整套动作。这些看似简单的动作,对机器人而言却是一项不小的挑战,尤其是像按咖啡机按钮这样需要精确到毫米级的操作,或是处理软质杯子这样仿真方法难以解决的问题。
(以上内容来自清华大学交叉信息研究院博导,清华大学视觉与具身智能实验室主任,千寻智能联合创始人高阳于2024年12月18日在第二届具身智能产业发展论坛发表的《具身智能中的数据瓶颈》主题演讲。)
本文地址:https://auto.gasgoo.com/news/202412/23I70414351C106.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921














