

盖世汽车讯 在计算机视觉的一些应用中,例如增强现实和自动驾驶汽车,估计物体和相机之间的距离是一项重要任务。聚焦/散焦深度是利用图像中的模糊作为线索来实现这一过程的技术之一。聚焦/散焦深度通常需要一堆以不同焦距拍摄的同一场景的图像,这种技术称为“焦点堆栈”。
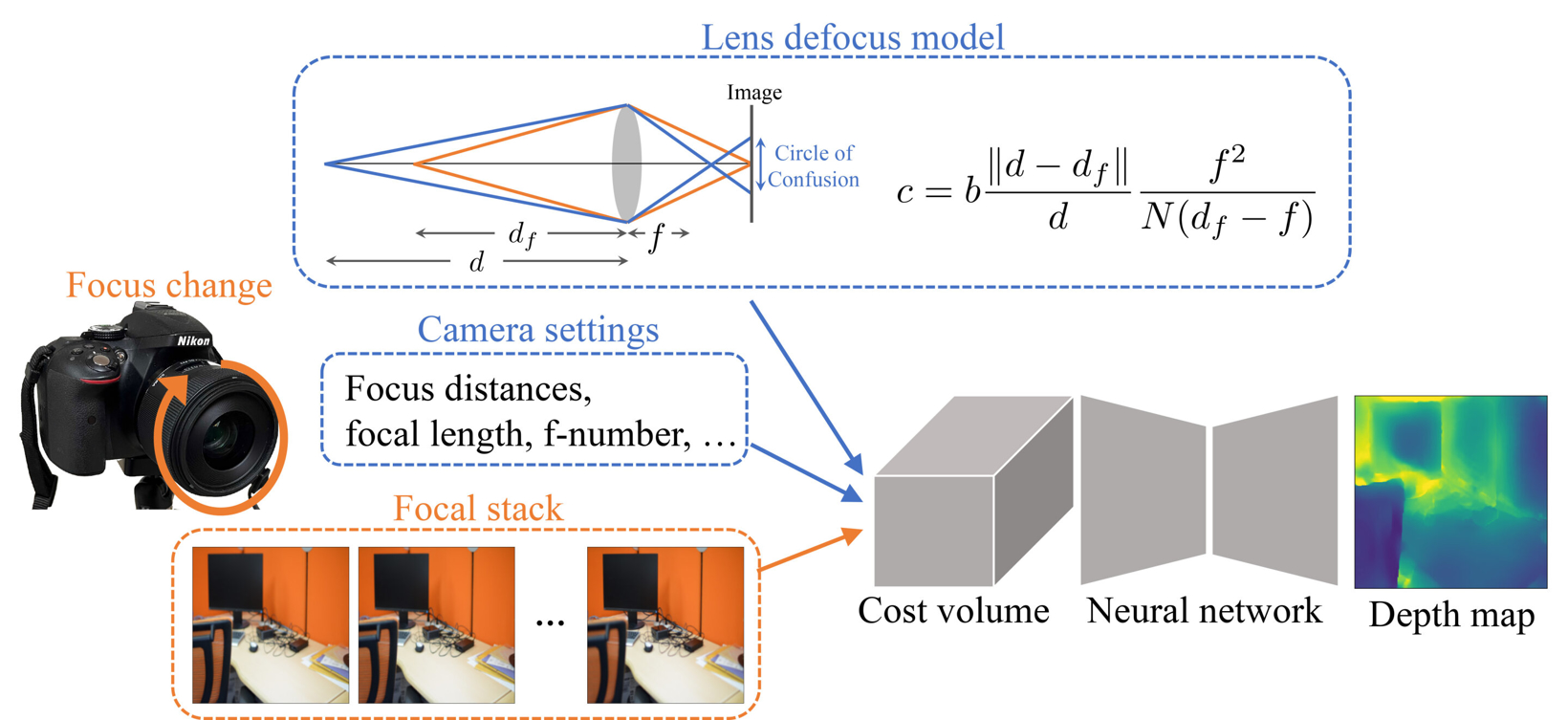
在过去的十几年里,科学家们提出许多不同的聚焦/散焦深度方法,其中大多数可以分为两类。第一类包括基于模型的方法,使用数学和光学模型根据清晰度或模糊度来估计场景深度。然而,此类方法的主要问题是它们无法处理无纹理的表面,而无纹理的表面在整个焦点堆栈上看起来几乎相同。
第二类包括基于学习的方法,可以训练这些方法以有效地执行聚焦/散焦深度,即使对于无纹理的表面也是如此。然而,如果用于输入焦点堆栈的摄像头设置与训练数据集中使用的摄像头设置不同,这些方法就会失败。
据外媒报道,日本研究人员克服了这些限制,开发出创新的聚焦/散焦深度方法,可以同时解决上述问题。该相关研究由日本奈良先端科学技术大学院大学(Nara Institute of Science and Technology,NAIST)的Yasuhiro Mukaikawa和Yuki Fujimura领导,且已发表在《International Journal of Computer Vision》上。
*特别声明:本文为技术类文章,禁止转载或大篇幅摘录!违规转载,法律必究。
本文地址:https://auto.gasgoo.com/news/202402/20I70382937C409.shtml
好文章,需要你的鼓励
联系邮箱:info@gasgoo.com
求职应聘:021-39197800-8035
简历投递:zhaopin@gasgoo.com
客服微信:gasgoo12 (豆豆)

新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921














