
盖世汽车讯 理解整体3D图片是自动驾驶汽车(AV)感知的重大挑战,会直接影响以后的活动,如规划和地图创建。由于传感器分辨率低以及视野小和遮挡造成的局部观察使得获取关于实际环境的精确和全面的3D信息具有挑战性。语义场景补全(SSC)是一种从稀疏观察中联合推断整个场景几何和语义的方法,旨在解决这些问题。可视区域的场景重建和受阻部分的场景幻觉是SSC解决方案必须同时处理的两个子任务。人类很容易根据不完美的观察来推理场景几何和语义。
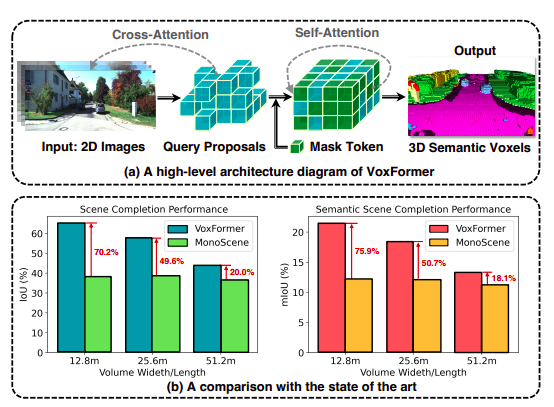
尽管如此,现代SSC技术在驾驶场景中的性能仍然低于人类感知。LiDAR是当前SSC系统中提供精确3D几何测量的主要模式。然而,摄像头的价格更低,且可以提供更好的驾驶环境视觉指示,而LiDAR传感器成本更高且不够便携。据外媒报道,国外研究小组基于MonoScene开发出VoxFormer,对摄像头的SSC解决方案进行进一步的研究。
图片来源:arxiv.org
其中MonoScene使用密集特征投影将2D图片输入转换为3D。然而,这样的投影给出了可视区域中空的或遮挡的体素2D特征。例如,被汽车覆盖的空体素仍然会获得汽车的视觉特征。
*特别声明:本文为技术类文章,禁止转载或大篇幅摘录!违规转载,法律必究。
本文地址:https://auto.gasgoo.com/news/202303/6I70332942C409.shtml
联系邮箱:info@gasgoo.com
客服QQ:531068497
求职应聘:021-39197800-8035
新闻热线:021-39586122
商务合作:021-39586681
市场合作:021-39197800-8032
研究院项目咨询:021-39197921
版权所有2011|未经授权禁止复制或建立镜像,否则将追究法律责任。
增值电信业务经营许可证 沪B2-2007118 沪ICP备07023350号














